Cette année encore, Sedona était présent au DEVOXX France, représentée entre autre par moi-même. Dans ce blog nous verrons quelques résumés des différentes conférences auxquelles j’ai pu assister. Ce ne sera évidemment pas exhaustif, mais cela peut donner envie à certains d’approfondir les sujets en fouillant sur le net, car beaucoup de conférence s’y trouve ainsi que des tutoriels et du code exemple.

Mercredi 5 Avril
University CQRS/ES from scratch (Emilien Pecoul et Florent Pellet)
L’idée de ce livecode est de démontrer comment on peut se focaliser sur les problématiques métiers afin de supprimer les problématiques techniques que l’on rencontre sur une application en couche même de petite taille. Ainsi la complexité d’un logiciel refléterait la complexité fonctionnelle et non technique. On verra en quoi l’event sourcing et CQRS permettent justement cette approche.
Pour illustrer cette approche, un livecode fera émerger une application « twitter-like », afin de montrer les concepts de base et montrer qu’on a pas besoin de framework spécial ou de langage de programmation spécifique. L’approche sera très simple, on abordera pas des choses comme la gestion de charge, de l’asynchronisme etc…. afin de rester simple et se focaliser sur les concepts basiques.
Un Architecte qui ne code pas est inutile
L’university commence sur comment se développe une application chez un client au sens classique. Un architecte (qui ne code pas :p) explique au client ce qu’il doit mettre en oeuvre afin de développer une application et on verra comment une approche classique de développement va rapidement complexifier l’évolution d’une application dans le temps.
Le métier exprime ses besoins (fonctionnalités) pour le démarrage de l’application, ils auront besoin de créer des messages (tweet), de les retweeter, de les liker de les supprimer et enfin d’afficher des messages sur une timeline. Dans cette approche classique, l’architecte va donc mettre en place un modèle de données relationnel classique avec trois tables Utilisateur, Message et une table de jointure UtilisateurMessageLiked. Puis il va définir une architecture en couche classique (Vue, Controller, Services, Modèle). Pour modéliser la base on utilisera bien évidemment un ORM.
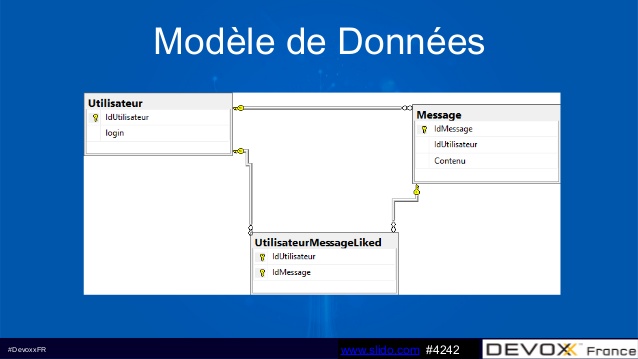
Une première problématique par rapport à ce type de conception apparaît, c’est la montée en charge, car la modélisation telle qu’elle est faite posera des problèmes de grappe d’objet qui vont vite devenir énorme. Mais l’architecte à réponse à cela avec le lazy loading et un système de cache.
Le temps passe, les développement avancent et une fonctionnalité oubliée apparaît, l’annulation de like. Pas de problème on modifiera la table de liaison dans laquelle on rajoutera des champs pour la gestion de suppression de like. Seulement les développements se verront allongés et complexifiés. On voit bien que la complexité apparaît rapidement sur des cas d’utilisations simples et le délai de livraison en sera impacté.
Dans cette façon de concevoir on se rend compte aussi que la notion de temps n’apparaît pas. Dans le modèle mis en place, on est capable de connaitre l’état d’un objet, mais comment avoir sa représentation dans le temps? Comment pouvoir avoir une photo à un instant t de l’état de l’enchaînement des actions sur un message?
Pour pallier à cela on va s’orienter sur une approche événementielle. Au lieu de stocker des états on va stocker des événements.

Avec cette approche on sera capable de dire quel est l’état d’un message à un instant t. Est-il like, unliked ?…
D’où le choix de mettre en place de l’event sourcing, tous les changement d’état de l’application seront stockés comme une séquence d’évènements.
Nous pourrons donc interroger ces événements, mais aussi utiliser le journal des événements pour reconstruire les états passés, et on pourra ajuster automatiquement l’état pour faire face aux changements rétroactifs.
En somme l’utilisateur va exécuter des commandes sur l’application qui vont déclencher des événements et ces événements auront pour action d’enrichir l’historique des actions sur un message.
On abordera par la suite l’approche CQRS qui permet de répondre à ce genre de problématique, on pourra séparer le chemin de lecture et d’écriture, c’est à dire que l’écriture correspondra à l’enregistrement d’exécution d’événement et la lecture permettra d’avoir accès à un état à un instant t (projection).
Pour bien concevoir cette approche, nos conférenciers mettent en avant la conception DDD (Domain Driven Developpement) qui permettra de concevoir des aggrégats (message) auto-suffisant, et nous propose la lecture du livre de Eric Evans.
On ressort de cet conférence, en ayant vraiment constater que plus que les outils c’est la conception qui compte.
Java EE, Microprofile, Typescript et Angular (Antonio Goncalves et Sébastien Pertus)

Cette université, très technique est destinée à un public de développeur, elle met en avant la conception de microservice en s’appuyant sur le nouveau concept de micro profile.
Des profils ont été ajoutés dans Java EE 6 dans le but de définir des sous-ensembles de spécifications Java EE à des fins spécifiques. Jusqu’à présent, il n’y a que 2 profils, le profil « full », qui contient toutes les spécifications Java EE et le profil « Web » plus petit, qui définit un sous-ensemble de spécifications pour les applications Web.
Jusqu’à présent, le Micro Profile ne fait pas partie de la spécification Java EE et n’est donc pas un profil officiel. Mais cela changera lorsque la définition du profil atteindra une certaine stabilité. Nous en sommes à la version 1.0, la version 1.1 et 1.2 sortiront courant 2017.
La première version du Micro Profile ne comprend que CDI, JAX-RS, qui utilise la spécification Servlet, et JSon-P. C’est évidemment le strict minimum des spécifications Java EE requises pour implémenter un microservice qui utilise une API REST pour exposer les ressources en tant que documents JSON.
Si vous préférez utiliser XML au lieu de JSON, vous pouvez, bien sûr, utiliser JAX-B, qui fait partie de Java SE et ne nécessite aucune spécification Java EE supplémentaire.
La version actuelle du Micro Profile inclut seulement un petit nombre de spécifications et plusieurs pourraient être ajoutés à l’avenir. Vous pouvez fournir des commentaires sur les spécifications que vous souhaitez avoir dans le Micro Profile sur microprofile.io.
La démonstration de la mise en place de microservice en s’appuyant sur le microprofile reposera sur wildfly-swarm. Wildfly-swarm fournit un serveur autonome MicroProfile pour déployer toute application .war conforme.
Il est à noter que Wildfly-swarm propose déjà d’autres fractions comme JPA, Swagger et bien d’autres. (Wildfly Swarm user guide)
L’idée de Micro Service dans Java EE provient de sa genèse: le modèle de composant EJB était un composant Micro: il suffit d’intégrer le code métier nécessaire, aussi petit que possible, l’empaquetage comme unité dans un seul livrable, un lien avec d’autres composants EJB via RMI / IIOP et le conteneur s’occupera du reste. Le modèle EJB était micro … pas le conteneur.
Depuis, les conteneurs Java EE ont évolué. Ils sont plus légers, plus petits, plus rapides… Donc, avoir un Micro Profil s’impose tout naturellement : micro composants fonctionnant dans un micro-conteneur.
Et comme Java EE est modulaire par conception, Java EE est une multitude de spécifications, chacune évoluant à leur propre rythme. Maintenant il suffit d’utiliser simplement ceux dont vous avez besoin.
Grace à cela on peut produire des jar exécutable embarquant le strict minimun des briques JEE et autres pour pouvoir mettre en place des micro services.
La suite de la conférence nous montrera comment implémenter des micro-services avec Wildfly Swarm et le miroprofile, comment configurer le serveur…
A cela s’ajoutera la mise en place d’un frontal Angular qui interrogera les différent s micro-service développés. Donc on verra l’utilisation de angular-cli pour démarrer un projet Angular, ajouter des services, des composants et autres grâce à ce dernier. Les avantages de Typescript seront revus en séance.
De plus on verra comment implémenter des clients angular pour micro service simplement avec l’utilisation de swagger.
Nous verrons aussi comment résoudre les problématique CORS avec les Interceptors fournit par JAX-RS. (ContainerRequestFilter, ContainerResponseFilter)
Puis la séance se terminera en nous montrant comment implémenter des api JSON avec {json:api} et le concept de HATEOAS mais aussi un rappel sur les Etag HTTP afin de gérer le cache côté client et éviter trop d’appel http sur le backend pour récupérer des ressources n’ayant pas été modifiées depuis le dernier appel.
JAVA 8 c’est bien Javaslang c’est mieux (Mathieu Ancelin)

Avec l’arrivée des lambdas et des streams dans Java 8, on s’est dit l’ère de la programmation fonctionnelle est là! Seulement on se rend compte que Java 8 ne fournit pas suffisamment d’outils pour éviter des contournement, du code trop complexe et verbeux etc… Java 8 offre peu de structure fonctionnelle, pas de tuples et les optional ne sont pas serializable.
D’où Javaslang! C’est une librairie empruntant pas mal d’idée de Scala et permettant de les appliquer dans le monde Java. Javaslang met à disposition :
- Tuples :
- Il n’existe pas d’équivalent direct d’une structure de données de tuple en Java. Un tuple est un concept commun dans les langages de programmation fonctionnels. Les Tuples sont immuables et peuvent contenir plusieurs objets de différents types de manière sûre. Javaslang apporte des tuples à Java 8. Les Tuples sont du type Tuple1, Tuple2 à Tuple8 selon le nombre d’éléments qu’ils doivent prendre. Il existe actuellement une limite supérieure de huit éléments. Nous accédons à des éléments d’un tuple comme un tuple._n où n est similaire à la notion d’index dans les tableaux.
- Future :
- est un résultat de calcul qui devient disponible à un moment donné. Toutes les opérations fournies ne sont pas bloquantes. L’ExecutorService sous-jacent est utilisé pour exécuter des gestionnaires asynchrones, par ex. Via onComplete. Un furur a deux états: en attente et complété.
- Lazy :
- est un conteneur qui représente une valeur calculée lazy, c’est-à-dire que le calcul est reporté jusqu’à ce que le résultat soit requis. En outre, la valeur évaluée est mise en cache ou mémorisée et renvoyée à nouveau chaque fois qu’il est nécessaire sans répéter le calcul.
- Pattern Matching :
- est un concept natif dans presque toutes les langages de programmation fonctionnelles. Il n’y a rien de tel dans Java pour l’instant. Au lieu de cela, chaque fois que nous voulons effectuer un calcul ou retourner une valeur en fonction de l’entrée que nous recevons, nous utilisons plusieurs instructions if pour résoudre le bon code à exécuter.
- Collection immuable :
- L’équipe de Javaslang a mis beaucoup d’efforts dans la conception d’une nouvelle API de collections qui répond aux exigences de la programmation fonctionnelle, c’est-à-dire la persistance, l’immutabilité. Les collections Java sont mutables, ce qui en fait une excellente source d’échec du programme, en particulier en présence de la concurrence.
-
Option serializable :
- Option est un conteneur d’objet dans Javaslang avec un but final similaire à celui de Optionnal en Java 8. L’option de Javaslang implémente Serializable, Iterable et possède une API plus riche. Comme toute référence d’objet en Java peut avoir une valeur nulle, nous devons généralement vérifier la nullité avec les instructions if avant de l’utiliser. Ces contrôles rendent le code robuste et stable.
Exécutez vos applications Angular hors navigateur (Wassim Chegham)
Présentation de Angular Universal qui est le module officiel d’Angular permettant d’ajouter entre autres le support du server-rendering ou facilité la gestion du SEO à nos Web apps. Mieux encore, avec Angular Universal il sera possible d’exécuter une même application Angular dans plusieurs environnement (navigateur, Web Worker, serveur, raspberry-pi…).
- Meilleure performance perçue
- Les utilisateurs de votre application verront instantanément une vue créée par le serveur qui améliore considérablement les performances perçues et l’expérience utilisateur. Selon la recherche de Google, la différence de 200 millisecondes seulement en performance de charge de page a un impact sur le comportement de l’utilisateur.
- Optimisé pour les moteurs de recherche
- Bien que Googlebot rende et rend les sites les plus dynamiques, de nombreux moteurs de recherche s’attendent à un HTML simple. Le pré-rendu côté serveur est un moyen fiable, flexible et efficace pour s’assurer que tous les moteurs de recherche peuvent accéder à votre contenu.
- Aperçu du site
- Assurez-vous que les médias sociaux affichent correctement une image d’aperçu de votre application.
La solution est encore naissante, car il va falloir l’adapter aux différents backend existant (Java, C#, PHP etc…)
Jeudi 6 Avril
Java 9 (Jean-Michel Doudoux)
Jean-Michel Doudoux nous fait découvrir les nouveautés de Java 9, cela étant la modularisation Jigsaw (jsr 379 et 376), à l’origine prévu pour java 7, étant une évolution majeure, ne sera pas abordée. Jean-Michel Doudoux avait énormément de chose à nous faire partager ce qui a rendu la conférence très dense.
Changement mineurs
- try-with-resources, le développeur n’a plus besoin de redéfinir la variable si cette dernière est en réalité finale.
- il est autorisé d’écrire des méthodes privées dans les interfaces afin de partager du code tout en respectant ainsi l’encapsulation.
- l’utilisation de l’opérateur diamant (<>) dans les classes anonymes est possible
- le caractère
_(underscore) ne peut plus être utilisé seul comme variable car il devient un mot clé du langage (pour un usage à venir dans les lambdas, déjà warning dans Java 8)
Nouvelles APIs
- la Stack-Walking API : permet de récupérer la stack trace du thread courant, de naviguer et d’interagir avec ses éléments. En Java 8 et versions antérieures, la méthode getStackTrace de la classe Thread permettait déjà d’obtenir la stack trace mais n’offrait pas la même richesse de filtres, d’assertion et de récupération (stack trace courte ou complète). A présent avec cette API lors d’une erreur, il est possible de filtrer les classes en supprimant par exemple toutes les mentions de framework/proxies pour ne conserver que les classes métiers de l’application.
- les Reactive Streams dans l’API Flow apparaissent. C’est 4 interfaces et une classe qui capture le cœur du framework Reactive Streams (publish-subscribe).
- l’API Process, qui date de Java 5, est enrichie de l’interface ProcessHandle qui permet d’obtenir le processus courant avec ses informations (le PID, le nom du processus, l’utilisateur qui l’a lancé, le chemin, l’utilisation des ressources etc.) et le déclenchement de code lors de la terminaison du processus lancé (
onExit). Il est aussi à noter que désormais il est possible de créer en une seule ligne des collections immuables.On pourra utiliser simplement la méthode of des interfaces Set.of(« a », « b », « c »). Par contre il n’existe pas de type spécifique pour les collections immuables, Jean-Michel Doudoux conseille d’utiliser une convention de nommage pour les collections mutables et immuables. - l’API Stream, les streams se voient dotés des méthodes takeWhile et dropWhile qui limitent les streams en passant une fonction plutôt qu’une valeur en dur. Et à noter la méthode onSpinWait sur la classe Thread qui permettra de réduire la consommation de CPU.
Evolution des outils du JDK
Le but est de simplifier les outils du JDK qui trainent des choses historiques et donc d’harmoniser entre autre les options de la ligne de commande avec un style GNU (-- pour les options longues, un seul tiret et une lettre pour la version courte). Les répertoires du JDK et du JRE sont réorganisés pour arborer une structure plus simple et similaire (bin, lib, conf, jmods).
De plus :
- Une autre nouveauté présentée, le MRJAR pour Multi-release jar files. Avant pour livrer une classe compilée pour chaque version de Java, il fallait fournir un jar pour chaque version. A présent, un jar peut contenir plusieurs fichiers .class d’une même classe. La version courante se situe à la racine tandis que les autres versions sont dans META-INF/versions/NUM_VERSION. Pour être pris en compte, l’instruction Multi-Release: true doit être ajoutée dans le fichier MANIFEST.MF.
- Un REPL (Read Eval Print Loop) est enfin prévu et il se nomme JShell. Disparition de Jhat
- Java DB ne sera plus fournit en standard
- Certaines démo et exemple sont retirés
- Nouveau format de version de la JVM, Le versionning sera plus simple en s’inspirant du versionnage sémantique. La version est composée de 4 parties séparées par un point :
$MAJOR.$MINOR.$SECURITY.$PATCH. - La javadoc générée en HTML5, rendra une vue par package ou par module jigsaw et fournit une recherche en JavaScript coté navigateur.
- Possibilité de charger les fichiers .properties en UTF8 avec la classe PropertyResourceBundle.
- Support de SHA-3 (SHA3-224, SHA3-256, SHA3-384, SHA3-512).
- Du nettoyage est également fait en marquant les applets comme @deprecated (mais sans date de retrait).
- Avec la JEP 182, Java ne supportera que les 3 versions précédentes.
Il est prévu que Java 9 sorte le 27 juillet (jour de mon anniversaire ^^), en attendant il est possible de télécharger les versions Early Access ici.
RxJava, RxJava 2, Reactor : Etat de l’art des Reactive Streams en Java (David Wursteisen)
Avant les systèmes d’information étaient auto-suffisant, alors que maintenant ils sont tous interconnectés que ce soit pour du Backend ou du mobile. (un mobile fonctionne grâce à internet et utilise par exemple des systèmes type GPS externe…)
Pour limiter le couplage entre ces systèmes il faut être asynchrone. Mais écrire du code asynchrone n’est pas si simple qu’il y parait et cela peut vite devenir compliqué.
Les Futur expose une méthode GET et si on l’utilise au mauvais moment on bloque notre système. Avec un ensemble de Futur c’est compliqué d’avoir l’orchestration optimale. Si on appel le Futur le plus lent on bloque toute la chaine. Pour limiter ce problème on peut utiliser des callbacks, sauf que l’empilement de callback peut devenir vite compliqué (« calback hell »).
Rappel du problème d’un appel synchrone à un service distant, on fait un appel et on bloque en attendant la réponse. Par exemple un site web appel un service distant, celui-ci est lent et met un peu de temps à répondre, puis la réponse tardive arrive et le site appel un deuxième service qui met moins de temps mais un peu quand même. La succession de ces deux appel va avoir un effet sur l’éxpérience utilisateur, celui-ci a le sentiment que le site réagit lentement (voir bloque) et du coup risque d’abandonner, voir va aller chez la concurrence. D’où l’approche asynchrone qui va permettre de ne pas bloquer le site web pendant que les appels aux services se font en background. L’utilisateur aura l’impression que le site est fluide et ne bloque pas.
L’asynchronisme est bien nécessaire, donc comment faire pour écrire du code asynchrone facilement?
Différentes approches :
- VERT.X
- akka
- Reactor
- RxJava
- RxJava 2
- Ratpack
Celles-ci convergent toutes vers un standard les Reactive Streams. C’est simplement un jeu d’interface qui expose un contrat et les implémentations cités ci-dessus vont y répondre. Les RS sont simplement un pont entre les implémentations.
Le contrat Reactive Stream :
- onSuscribe (démarrer un abonnement à un flux)
- onNext (notification 1-n sur un nouvel événement)
- onComplete (notification ou pas de la fin du flux)
- onError (notification d’erreur sur le flux)
Quand est-il de RxJava, RxJava 2 et de Reactor par rapport à ces RS?
RxJava n’est pas compatible avec RS. Nécessité d’utiliser un adaptateur( RxJavaReactiveStreams). L’incompatibilité vient de la différence de nommage. Par exemple RS spécifie onComplete alors que RxJava spécifie onCompleted.
Grace au RS, Reactor peut utiliser RxJAva2 et réciproquement.
Ces deux implémentations sont des APIs pour manipuler des événements de manière synchrone ou asynchrone à travers un flux d’événements. Sur ce flux d’événement on pourra utiliser des opérateurs pour modifier ces événements (clic de souris, appel de service…).
Exemple : on veut récupérer les véhicules (premier flux) et les vaisseaux de Luke SkyWalker par un appel réseau. On utilise les Observable pour cela. On définit ces deux flux d’événements et on les fusionne (merge). Puis pour déclencher les appels proprement dit on appel la méthode subscribe. Du coup on se retrouve avec un nouveau flux d’événements qui est l’ensemble (sur lequel on peut bien évidemment manipuler des sous flux)
Du coup on se retrouve avec du code plus simple.
Historique des projets
- Création des Reactive Extension par Microsoft (Eric Mayer)
- Création de RxJava par Netflix en s’appuyant sur les reactive extension
- En parallèle un universitaire, David Karnok participe en proposant des améliorations…
- Le lead dev de chez Netflix par chez Facebook, donc que va devenir RxJava, qui va le reprendre, est ce que Netflix va l’abandonner etc…
- David Karnok reprend le lead sur RxJava et met en place RxJava 2
- En parallèle Pivotal met en place le projet Reactor, et David Karnok participe aussi
RxJava est une technologie éprouvée, Netflix l’a utilisé en production. Reactor profite d’autant plus de l’expérience de RxJava avec la participation de David Karnok.
Quels sont les objets qu’on manipule dans ces bibliothèques?
RxJava :
- Observable (notification 0-n fois puis signal de fin, plusieurs événements et une erreur, juste une erreur voir juste un signal de fin, c’est très souple). Il supporte la back pressure mais a été ajoutée après coup.
- Single (soit événement soit une erreur), idéal pour représenter un webservice
- Completable (soit le flux se termine soit on a une erreur), correspond très bien à un processus d’arrière plan
Par exemple on écoute un websocket (observable car on peut avoir différents type d’événement), qui déclenchera une réponse à partir de trois webservices (single) puis exécutera 2 jobs séquentiellement (completable).
RxJava 2 :
- Les types cité pour RxJava
- Maybe (proche de optionnal en Java 8), il expose comme signaux un événement ou une fin ou une erreur, pas de mixe possible entre ces différents signaux.
Qu’est ce que la Back pressure? Un fournisseur répond à un client, mais comme ce dernier ne peut absorber la quantité d’informations envoyées par le premier, il lui dit de se calmer en lui envoyant un message pour ralentir la cadence afin que le consommateur puisse absorber.
Comme avec RxJava cette notion a été ajoutée sur le tard, c’est compliqué pour un développeur de savoir d’ou vient un problème de BackPressure (MissingBackPressureException)
Du coup avec RxJava 2, aucun des types précédemment cité ne gère la BackPressure, et un nouveau type arrive, le Flowable qui lui gère ce concept. Un Observable qui gère la BP.
Reactor :
- Flux (un ou plusieurs événement), s’approche fortement de Flowable
- Mono (un seul événement)
Les deux supportent la BP.
Flux et Flowable implémentent l’interface Publisher. Du coup on peut faire cohabiter RxJava 2 et Reactor.
Le catalogue des opérateurs est assez identique entre les 3 bibliothèques et très riche. Reactor ne permet pas de créer de nouveau opérateurs mais RxJava 2 oui.
Migration RxJava vers RxJAva 2 simple. Il existe des adaptateurs
Reactor se base sur Java 8 alors que RxJAva 2 sur Java 6 (pour assurer la compatibilité avec Android). Donc pour utiliser une notion de temporalité on pourra dans Reactor utiliser le type Java 8 Duration alors que dans RxJAva ce sera TimeUnit.
Contexte d’éxécution
Avec les Schedulers. En mode multi-thread on a pas de garantie de la terminaison dans l’ordre d’évènement, alors que en mono-thread si.
C’est intéressant pour les Backend et pour les applications Android.
On a des outils avec RxJAva 2 et Reactor pour switcher de contexte d’éxécution notamment avec la méthode observeOn.
Les schedulers en Reactor ont un nommage technique alors que c’est fonctionnel dans RxJava.
Difficulté de Debug de code asynchrone :
- RxJavaHook rajoute enaleAssemblyTracking
- Par contre dans RxJAva 2 il faut utiliser RxJava2Extension (copie de Reactor)
- Reactor va plus loin avec checkpoint, opérateur permettant de préciser un label. Mais attention cela dégrade les performances.
La performance?
RxJava et Reactor détectent qu’on peux utiliser une file de traitement au lieu de deux. La fusion diminue la consommation mémoire et optimise les performances. En terme de Benchmark, RxJava 2 et Reactor sont aussi performant que les streams Java 8.
Les tendances d’utilisation?
Côté mobile la tendance est fortement sur RxJAva mais une migration sur RxJAva 2 s’amorce de manière très significative.
Sur les backend (Couchbase, Hystrix…), la majorité des projets sont sur RxJava et pas de tendances de migration.
Par contre sur les projets Spring, la tendance est à passer sur Reactor.
Spring 5 (Stéphane Nicoll)
- Reactive avec le support de Reactor
- Routers
- Kotlin
- Servlet 3.1
Node.js comme les grands (Romain Maton)
Retour d’expérience sur l’utilisation de Node.js dans la vraie vie et qu’est ce qu’on doit/peut utiliser comme outils pour que tout se passe bien.
Installation
Gestion des packets :
- npm
- yarn (beaucoup plus performant, téléchargement parallèle, résolution en amont et un cache)
Task runner :
- gulp
- grunt
- npm scripts
Packaging :
- Webpack
- Brunch
- Browserify
Configuration
Languages :
- EmacScript 6/7/8
- Typescript
Style de programmation :
- Callbacks avec asynch.js
- promise avec bluebird
- générateur avec co
- async/await avec babel et natif dans V8
Outils d’analyse de code :
- eslint
- jslint
- jscs
Production :
- Gestion de log :
- tout logger
- identifiant unique dans les headers des request
- Request in/out, tout logger
- Latence ou temps hors application
- Garder les logs en mémoire comme Netflix et flusher sur erreur
- Utiliser le profiler V8
- intégrer à V8
- donne le temps passé dans chaque couche
- Profiler via js :
- Module V8 profiler ou node profiler
- Head dump
- Flamegraph :
- visualisation complète de l’application
- CPU/mémoire/…
- linux perf, OSX dtrace et Windows Xperf
- Automatisation :
- profiling à la demande
- SIGUSR2
- Heap Dump
- poser des alertes
Puzzler :
Il est souligné que connaitre le fonctionnement de l’event loop peut rendre service, cela peut être utile de savoir ce qui s’exécute et dans quel ordre (timers, I/O callbacks, idle/prepare, poll, check, close callbacks). Attention à nextTickQueue qui s’exécute hors event loop et immédiatement après l’opération.
Performance :
On peut gérer les processus I/O au travers de libuv (appels I/O et callbacks en s’appuyant sur un thread pool de 4 threads). Attention manipuler ce genre de chose que si vraiment nécessaire, cela peut devenir très problématique.
Puis sera abordé comment fonctionne la compilation V8. V8 prend notre js et le convertit en code machine, démarrage non optimisé puis pré-chauffage et optimisation. Le JIT initial est très rapide car il fonctionne sans type, et V8 lui si. Grace à cela il peut faire de l’inline cache. Plutôt que de repasser dans toutes la boucle qui mène à la fonction, on a un pointeur directement sur la fonction parce que en entrée on a les même types. Et il le sait grâce au hidden class.
Pour optimiser son code, on peut privilégier des fonctions mono-morphiques, car les poly/mega-morphique sont quasi non optimisables. Privilégier les void 0 au lieu des undefined et faire une for-loop au lieu d’un foreach (3/4 fois plus rapide). Et pour analyser le gain il existe pas mal d’option sur node avec –v8-options.
Les fuites mémoires :
- attention au référence sur le root global, car c’est pas libérable par le GC
- Au niveau de l’event emitter si vous positionnez un événement qui a un call back qui porte le contexte de l’objet, le GC ne pourra pas non plus libérer les objets car potentiellement un événement pourra être lancé sur l’objet.
- Les comparaisons de heap pourront nous aider
Penser à faire de l’asynchronous batching/caching qui consiste à ne pas faire différent traitement sur un différent appel qui demande le même résultat (demande partagée). Le premier appel fait calculer le résultat et le deuxième avec les mêmes paramètres d’entrée se verra servir ce même résultat sans recalcul, le deuxième appel est juste stocké sans lancer de traitement car celui-ci est en cours. On prendra deux fois moins de ressource CPU. C’est le concept d’une queue en programmation asynchrone.
Sécurité :
Voir plugin Helmet, virer les entêtes type X-Powered-By etc…
Failles sur les dépendances de notre projet : NSP permet de lister les failles et indique les versions de fix. Sinon utiliser snyk qui lui applique directement les fix. Par exemple sans mise à jour on peut s’exposer à une découverte des répertoires de notre serveur….
Tests :
- Mocha
- Casper
- Nightwatch (qui pilote du selenium)
- Couverture avec istanbul
Cette conférence montre bien qu’on peut faire du Node.js en production, nombre d’outils existe actuellement et c’est performant et monitorable. De plus la documentation est très riche.
Log me tender (Olivier Croisier)
Retour d’expérience sur les logs en java qui sont incontournables dans toute application. Pourquoi le log? Pour matérialiser un événement.
Le system.out… C’est une approche très simple pas industrialisée.
Première solution proposée, log4J qui a eu un influence extrêmement forte et qui en a fait découler les standards du log en java. Grace à lui on peut logger des string et des strings avec des exceptions.
Par la suite Java s’est dit qu’il allait standardisé log4J , en l’ajoutant à la jdk sauf que personne ne s’en est servit.
Puis est venu l’idée de faire une deuxième version de log4J2, mais est apparu plein de framework de log, et c’est là qu’en 2002 commons-logging apparait, mais c’est une API similaire à log4J.
Et le créateur de log4J a créée SLF4J qui s’intègre à tous les frameworks de log. Sauf que l’API reste quand même la même.
Problème :
- concaténer les chaines de caractères -> solution concaténation lazy (on concatène si on doit logger)
- évaluation immédiate des paramètres -> solution tester dans quel niveau de log on est pour logger (debug, info…) Sauf qu’on est couplé à la configuration de notre logger et ça prend de la place dans le code car c’est trois ligne de plus à chaque log, et c’est pas DRY (don’t repeat yourself). Autre solution c’est de dire qu’il nous faut des messages produits de manière lazy. Avec Java 8 on a les Supplier<String> qui un jour produiront une String, plus besoin de placeholder, on peut faire des concaténations avec +. C’est bien sauf que c’est implémenté par « tout le monde » sauf SLF4J… Le framework d’abstraction de log devient le facteur limitant. Pour y remédier on peut « Façader SLF4J » -> LogService
- Les factory statiques (pas testable, pas mockable, non configurable), il vaudrait mieux faire de l’injection de dépendance. Du coup on peut tester, mocker et faire de l’AOP avec pour par exemple optimiser ou le court-circuiter pour pas que le logger bloque l’application dans certains cas.
- Les frameworks de logs sont beaucoup trop bas niveau, ils ne sont pas DRY, et pas harmonisés (on ne peut pas garantir que deux informations similaires sont loggées de la même manière, c’est à la main de chaque développeurs). De plus le formatage des logs doit être harmonisé pour les besoins d’analyse futur de ces logs. On pourrait aussi avoir un système de log qui gère différent cas d’utilisations, si on veut du log pour la perf, la prod, ou le métier il faut qu’on ait deux, trois, quatre loggers.
Solution :
Un service de log de haut niveau, une façade pour les frameworks techniques de log, on se pose pas la question à quel framework on s’adresse. On pourra dire au service de log de prendre la notification de tel ou tel événements, donc il prendra le framework qui correspond bien selon. Cela permettra d’exposer une API se service métier, on lui passe l’info et le reste est géré par le service de log. On pourra profiter de Java 8 dans notre service de log même si le framework de log bas niveau qu’il exploite ne le gère pas.
Le logService :
- Les méthodes seront modernes avec les supplier Java 8
- Retro-compatibilité et extensibilité, on garde le log service fournissent les anciennes méthodes debug, info …
- SLF4J sera l’implémentation technique du service de log, c’est la façon la plus simple de rassembler les logs des frameworks de logs et de les rediriger vers un framework technique particulier
- Déclarer ce service comme n’importe quel service pour pouvoir l’injecter.
On définit l’interface avec les méthodes décider : log, debug, info etc…
Et on implémentera une classe de log qui s’appuiera sur SLF4J.
Puis il implémentera les factory associées en faisant attention à la rétrocompatibilité.
En conclusion, les logs aujourd’hui sont un peu le point noir en terme de production, c’est quelque chose qui est en pleine évolution car nous avons besoin d’analyse en temps réel, de faire des logs pertinents pour les micro services et Cloud et c’est encore mal industrialisé. Les frameworks et pattern date un peu et il n’y a pas grand chose en terme de spécifications dans les projets. Du coup on peut grâce à la sensibilisation Devops penser que cela va fortement évoluer dans les mois/années à venir.
Docker 2017 : nouveautés et perspectives (Vincent Demeester)
- Docker Edition : le binaire de base adapté pour des plateforme destop (MAC, Windows) et Cloud (Azure, Amazon, Google)
- Docker 4 Desktop : compatible MAC et Windows (gère le network, pas besoin de virtual box…)
- On peut avoir accès aux fonctionnalités expérimentales depuis le binaire classique
- docker-init : gestion des processus zombies
- Restructuration des commandes en ligne (docker ps -> docker container ls…)
- Rétro-compatibilité du CLI
- Possibilité d’utiliser des plugins
- Renfort de la sécurité sur swarm
- Compose to swarm : lancer un compose file sur un swarm plutôt que sur un noeud simple
Le Web multi-écrans en action (Hubert Sablonnière)
Pour la dernière conférence de fin de journée, petit moment de détente avec une approche sur le concept du multi écran sur un PC. Entre ceux qui travaille sur du multi écran (dev, designer…), ceux qui en aurait besoin pour des raisons professionnelles, cette conférence nous interroge sur le fait de ne pas utiliser plus que ça le multi écran alors que les besoins sont nombreux (présentation commerciale , donner des cours, chez le médecin…) et que cela ne soit pas encore dans les mœurs de la société actuelle. C’est à dire profiter de l’interaction multiple que peut permettre d’avoir plusieurs écran. Je suis chez le médecin et il me montre sur un deuxième écran ce qu’il analyse sur son premier écran, ou bien un architecte vous montre sur un écran ce qu’il conçoit sur le sien etc…
Par la suite nous verrons quelles sont les différentes techniques pour pouvoir manipuler différentes fenêtre en javascript et les positionner sur des écrans windows et nous en verrons aussi les limitations.
Vendredi 7 Avril
Mettre en place sa sécurité et sa gestion d’identité en 2017 (Sébastien Blanc)

Comment faire de l’authentification de nos jours? Nous allons parler d’identité, car de plus en plus notre identité réelle et notre identité numérique commence à se superposer. Les réseaux sociaux nous y incite (Facebook…). On est plus à l’époque des chat caramail, ou on pouvez être totalement anonyme avec des pseudos :).
Les réseaux sociaux ok! Mais pas seulement maintenant les services de l’état sont en ligne aussi par exemple, avec France Connect qui doit permettre d’utiliser tous ses services publiques, d’ou l’importance d’utiliser notre vrai identité.
Du point de vue du développeur comment gérer cela? On va pas s’occuper en permanence de la gestion des rôles et de l’autorisation. Et il faut aussi que du point de vue utilisateur cela reste agréable et qu’il n’ait pas besoin de se signer en permanence.
Sébastien Blanc notre conférencier nous présentera le produit KeyCLoak, qui permet la gestion d’identité et d’accès, de chez Red Hat chez qui il travaille.
Donc on verra que cette solution permet de sécuriser un front angular, un backend node ou JEE et comment sécuriser cela de manière simple.
Avant, on gérait la sécurité en mettant les infos dans sa base de données et on écrivait soit même ses formulaire de login et on gérait le chiffrage. Ce n’est pas forcément bien, on pollue le code, la base de donnée, en somme on couple les concepts. Laissons le métier au métier et la sécurité à la sécurité. Sinon dès qu’on détectera des failles, il faudra revisiter le code de toutes les applications ou on l’a géré à la main. Donc décentralisons, déléguons la sécurité!
Donc pour l’authentification , la gestion de l’identité et des rôles : on délègue.
Le concept c’est que lorsque on veut accéder à une ressource (un front angular, un service JEE…) celle-ci nous demande de nous authentifier auprès d’un service d’autorisation.
En terme de solution/protocole, il existe SAMLv2 qui transmet l’identité après authentification mais c’est vieux, lourd donc pas très adapté pour les webapp moderne. Donc si on démarre des nouvelles applications on évite SAMLv2. Il y a aussi Oauth2 mais ce n’est pas un protocole d’authentification c’est un framework qui ne gère pas l’authentification ni même l’autorisation, il décrit comment différentes parties peuvent déléguer un accès à une autre application. D’où OpenId Connect, une surcouche à Oauth2, qui amène tout ce qu’il manque à Oauth2. Il définit l’authentification, il transmet un ID token qui contient toutes les infos de la personne authentifiée, il gère la notion de session pour le SSO et aussi pour le single logout(déconnexion), il fournit aussi l’identité avec un endpoint, et un service de discovery pour pouvoir savoir ou se trouve le serveur OPENID connect.
La gestion du token ID (token d’identité) par OIC s’appuiera sur un token JWT. Plus compact que de l’XML, encodé en base 64, composé de trois partie un header, un payload et une signature. voir https://jwt.io/.
JWT est un peu une classe abstraite, car dès lors qu’on signe notre JWT, il devient JWS et on peut aussi et obtenir du JWE mais keycloak ne gère que le JWS et ne supporte pas encore le JWE.
Donc on est dans notre application angular, après s’être signé, ou on a un jeton récupéré de l’authentification et celui-ci nous permettra donc de questionner un service rest en lui transmettant le dit jeton.
Il existe plusieurs outils sur la marché pour la délégation d’identité :
- Oauth0
- Authockat mais services hostés
- Stormpath
- ForgeRock
- KeyCloak Out of the box solution
Gestion de l’authentification, par défaut OIC mais on peut faire du SAML v2 et du kerberos. On peut se connecter avec des comptes de réseaux sociaux, se logger sur un LDAP en passant par KeyCLoak. Quand l’utilisateur est loggé il peut gérer son propre profil.
Multiple adaptateur :
- Java :
- Wildfly, JBOSS
- Tomcat, Jetty
- Spring Boot, Spring Security
- Genereic servlet fileter pour WAS et autres
- JS
- NodeJS
Démo :
- Sécurisation d’une web app js qui appelle différents services, JAVA, Node, spring et aussi du serveur side.
CQRS/EventSourcing par la pratique (Clément Heliou)
c’est une conférence qui propose une approche par la pratique, Clément a bénéficié d’une expérience de deux ans dans une grande banque.
Event sourcing :
Pattern d’architecture, agnostique du language et du framework. On ne se concentre pas sur l’état courant de notre application mais sur la séquence d’état qui a permis d’arriver à cette état courant. Ces états sont des événements métiers, ce qui va faciliter la compréhension justement des acteurs métiers. On va faire ça parce que en reprenant cette suite d’événements on va pouvoir agréger l’état courant alors que en partant de l’état courant c’est difficile de savoir ce qu’il s’est passé. Un événement à une cause unique. (par exemple votre compte bancaire, la banque ne vous donne pas l’état du compte mais la suite/l’enchaînement d’événements qui se sont produit dessus, débit, crédit…)
Donc on peut se concentrer sur les changements d’état et non sur l’état en lui même. (Regain d’intérêt avec le DDD)
L’event sourcing sera aussi très intéressant pour un audit de notre application, car on pourra facilement sortir les événement qui se sont produit afin que des régulateurs puisse analyser ce qu’il s’est passé dans le système. Aussi l’analyse et le debug s’en voit faciliter, car on peut lire une séquence d’événement afin de reproduire ce qu’il s’est passé concrètement pour un utilisateur. On peut aussi faire de la reprise de données simplement, dans le cas d’une panne, on remonte une autre instance, et on rejoue les événements jusqu’à l’état précédent cette panne.
Exemple d’une application qui reçoit des commandes. Une commande est auto descriptive. Lorsqu’elle arrive sur l’application cela déclenche une fonction de décision, l’état courant de l’application et la commande vont déclencher un ensemble d’événements qu’on va stocker dans un event store. Après les avoir stocker on va déclencher une fonction d’évolution, on fait muter l’état de l’application. Il y a aussi une notion d’action qui est notre système qui fait quelque chose sur lui-même, l’évolution déclenche donc une décision qui générera des événements qui seront stockés à leur tour. Puis lorsque l’état de l’application sera stable on pourra publier ces événements vers l’extérieur, on parlera de jouer les effets de bords.
Il n’y a pas de fumée sans feu
La fumée c’est les événements donc il n’y pas d’événement qui n’est pas une cause unique, cause unique qui est une commande, donc pour tout événement on a une commande à mettre en face.
Dans la suite de la conférence on verra comment ce modèle a été mis en place pour une salle de marché.
Simplement, l’application va recevoir des prix (commande), ce qui déclenche une fonction de décision qui produira un prix reçu (événement à stocker) puis déclenche une fonction d’évolution qui déclenchera une ou des actions (Transférer prix) qui rédéclenchera une fonction de décision qui amènera à stocker un événement « prix tranféré ». Une fois le système stabiliser on publiera ces événements.
Voici l’architecture qui sera mise en place pour répondre à la logique évoqué ci dessus :
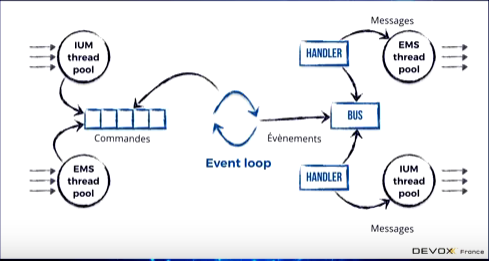
Des pools de thread vont être mis en place afin découter les messages qui arrive et les mettre dans une queue de commande. Puis un thread exécutera les comandes, une event loop, c’est à dire jouer notre fonction de décision, la fonction d’évolution, puis publier les événements sur un bus ou souscrive des handler qui eux vont jouer les effets de bords vers l’extérieur.
Pour mettre en place la queue de commande, ils se sont appuyer sur une Blocking queue car il y a plus de producteur de commande (mutlti-thread) que de consommateur (mono-thread) et ces premiers produisent beaucoup plus vite que ne consomme le deuxième. Donc si on a trop de commande, on bloque les producteurs tant qu’on est pas capable de traiter à nouveau des nouvelles commandes (mécanisme de back-pressure). Il faut noter que comme comme on est mono-threader sur le traitement d’une commande, il faut que ce processus soit extrêmement rapide (de l’ordre de la milli-seconde).
Clément évoquera le fait que si on commence dans l’event sourcing, il vaut mieux partir « from scratch » que d’une librairie ou d’un framework et au fur et à mesure de la montée en compétence et des erreurs commises, cela nous permettra plus tard de pouvoir choisir un framework/outil car on connait les problématiques.
Attention aussi au nommage des événements, il faut que le nommage colle le plus prêt possible du nommage métier. Tout le monde doit parler le même langage, aussi bien les techniques que les métiers. Cela a le mérite de simplifier les discussions, tout le monde parle le même langage.
En quoi CQRS (Command Query Responsibility Segregegation) va nous aider sur les problématiques d’event sourcing vue précédemment? Le CQRS c’est une vue d’écriture qui va modifié l’état de notre système et une vue de lecture qui va lire l’état du système. Si on reprend l’exemple du compte bancaire, les opérations de débit et de crédit vont modifier l’état de notre système, et la consultation de notre compte sur le site de la banque sera l’analyse de l’état du système.
On a deux problématique distinctes, on a pas les mêmes besoins pour l’écriture et pour la lecture. Dans l’écriture on va s’assurer qu’on a des données cohérentes, qu’on a des transactions ACID, avoir des choses normalisées. Alors qu’en lecture on veut plutôt des choses dénormalisées, des accès très performants, des vues… Les deux contraintes de lecture et d’écriture vont rarement bien ensemble, d’ou le découplage.
CQRS :
- performance de lecture
- maintenabilité
- s’intègre bien avec l’ES
Le CQRS a permis de répondre à une demande du métier de suivre en temps réel les transactions de l’application,des contrôles basique sur les client et autres donc répondre à du monitoring métier précis.

Pour reprendre l’exemple précédent on va positionner un handler sur le bus d’événement, et on envoi les evts vers un middleware (push api). Celui ci est une application qui se charge de l’agrégation des vues de lecture, et cette agrégation sera poussée via un websocket vers une IHM d’affichage, la console, qui est en angular. Aucune logique métier ne se trouve dans cette console on ne fait que afficher les informations reçu des agrégations. La logique d’agrégation est à un seul endroit. Attention comme on est sur des systèmes distribués, il se peut que l’ordre des événements ne soit pas ordonné, donc à chaque réception d’événement toute la logique de la vue est recalculée, si on reçoit un événement antérieur on récupère tous les événements pour les trier et cela permet d’avoir un état du système cohérent à tout instant.
Conclusion :
- Attention à ne pas coupler fortement la vue de lecture de la vue d’écriture. (Protobuf)
- Prendre le temps, faire des compromis (ne pas livrer tous les besoins métiers d’un coup), apprendre et améliorer.
Les bornes des limites : comment maintenir de la cohérence dans votre architecture microservices (Clément Delafargue)
Clever-Cloud : architecture de micro-service pour héberger des micro-services. Multi-technologie (php, java, ruby…)
On a des microservices, donc plein de serveurs d’application, plein de BDD etc… et comment on fait pour ne pas s’y perdre?
Pour quoi ne pas faire du monolithe et choisir de tout répartir, tout diviser, rajouter de la complexité, des appels réseau partout?… :
- Separation of concerns et ne pas dupliquer la logique métier.
- Réduire la taille du code (facile à prendre en main)
- Réduire la taille des équipes (synchroniser et livrer rapidement etc…)
- Les cycles de vies des applications deviennent indépendants (déploiements rapides, segmenter les erreurs qui ne foutent pas tout le système par terre)
- Scalabilté plus simple, on peut faire des choix différent sur chaque briques suivant les besoins.
- Pouvoir urtiliser autant de technos qu’on le veut suivant le besoin. Cela permet de pouvoir en plus tester des nouvelles technos, cela n’a pas d’impact sur la globalité du système.
- Multiplier les type de base de données, finit le temps de la grosse base relationnelle qui gère tout.
Cependant les monolithes conservent certains avantages. L’architecture micro est beaucoup plus complexe (bootstaper une archi micro c’est compliqué), il faut un réseau très performant.
Quelles question se poser pour faire ou non du micro-service :
- Capacité de provisionner rapidement des serveurs
- Il faut mettre en place un monitoring performant
- Pouvoir déployer rapidement en production
- Pour aller plus loin voir 12factor.
Il faut tout automatiser :
- le build
- l’injection de configuration
- les déploiements
- provisionner les différents environnements
Ne pas partager d’état mutable. Pas d’état persistent sur le file system (le file système peut être « buté » à tout moment)
Attention la complexité par contre ne sera plus présente dans votre code avec les micro-services mais va se déplacer en dehors, c’est à dire au niveau de l’interaction des différentes briques.
Il est important de connaitre les problèmes qui peuvent arriver. Savoir si quand on fait un appel c’est local ou distant. Limite et frontières doivent être explicitent. Plus on cache la complexité plus on accumule de la dette technique. Si complexité il y a, ne pas la cacher. Si le code est moins complexe que le problème, c’est qu’on est en train de se tirer une balle dans le pied.
Architecture hexagonale pour l’orientée objet est un très bon moyen de modéliser pour avoir de belles frontières.
Attention à la topologie de votre architecture, elle doit être explicite on doit savoir ou sont les choses et qui dépend de quoi, par contre votre micro-service doit être agnostique de la topologie, cela permet de les faire évoluer en isolation et de réduire le couplage. Pour ça il existe un protocole de service discovery super répartie, distribué, excellente perf : DNS (domaine name system)
Penser à bien documenter tout les protocoles, dès que deux choses se parlent, il y a un protocole, plus vous les documentez plus vous aurez tendances à bien les simplifier.
Attention à toutes les problématiques de serialization/deseralization, cela peut être source de nombreuse faille de sécurité. (Voir avro)
Conclusion :
- Automatiser
- Pas d’état
- Connaitre les limites réseaux
Les problèmes que l’on rencontre en microservice : configuration, authentification et autre joyeusetés (Quentin Adam)

IT automation : le développeur développe et pousse son code et là le packaging, le déploiement, la scalabilité etc… se font sans intervention de sa part.
Clever-Cloud : Remote code execution as a Service. Lors de la mise en place de la Road Map, il a fallu déterminer un niveau de sécurité en tenant compte que du code qui s’exécute chez clever-cloud peut attaquer en interne et en externe (d’autres client ou même clever-cloud), donc la problématique de sécurité sur les micro-services était primordiale. Chaque brique peut potentiellement attaquer d’autres briques, donc on doit segmenter le domaine d’action des micro-services.
Faire du micro-services cela veut dire aussi qu’on doit, voir même on est obligé, d’utiliser des multiple stacks technique. Par exemple on va développer les applications en JEE, mais le déploiement va se faire en script, on va lancer les VM en C etc…
On peut différencier le niveau de scalabilité pour chaque micro-services.
L’évolution des micro-services permet d’innover facilement, de maintenir et d’évoluer facilement
Architecture as a playground : celui qui arrive dans ce monde de lego doit pouvoir facilement ajouter les siens sans se poser de question, cela doit être simple. De plus les autres n’ont pas à s’en préoccuper.
Dès qu’on parle de deux micro-services qui communiquent, on ne peut plus parler de trusted network. La forteresse n’existe plus depuis longtemps. Donc chaque fois qu’on balade de l’information entre les deux serveurs, on doit authentifier, chiffrer et logger tout ce qu’il se passe pour avoir des pistes d’audit efficaces. Oublier l’idée que si on est dans un même réseau on est « safe »…
Plutôt que le request/reply choisir une communication interservices en mode message box, on envoie des messages. On peut aussi dupliquer les messages facilement, tous les trucs intéressant qui se passe on a les messages, ce qui fait qu’on peut intégrer des nouveaux services facilement en s’appuyant sur ces messages box et en abonnant un service à un autre plutôt que de modifier un service pour qu’il fasse appel à un autre. Tout message doit être dupliquable à la volée, on peut aussi du coup stocker ces message dans de l’analytique et faire de l’audit. Du coup http ne fait pas sens partout, c’est bien pour du question/réponse, mais il vaut mieux privilégier des choses comme rabbitMQ, Kafka, Redis…
Un micro-service doit doit fournir un service par lui-même, il ne doit pas pour le fournir passer son temps à communiquer avec d’autres services (exemple sur l’établissement de connexion TCP qui finit par créer des goulots d’étranglement lorsqu’il y a trop d’établissement de connexion). Du coup il vaut mieux partir d’une application « fat monolith » et la découper au fur et à mesure plutôt que l’inverse, c’est à dire refusionner des microservices (par exemple trop de micro-services qui partagent le même code, librairies partagées, c’est qu’ils sont mal conçus). Il faut diviser du code qui ne se parle pas.
La configuration :
- etcd
- consul
- …
Problème ce genre de configuration finit par devenir un SPOF (cluster etcd…)
Il faut que les logiciels changent de configuration à la volée, on doit avoir une approche sur de la mise à jour à chaud. C’est l’orchestrateur qui boot sur la nouvelle conf et qui bute l’ancienne. Par exemple on peut utiliser des variables d’env, et si on change on redémarre l’application. c’est beaucoup plus simple que de gérer un système discovery qui fait de l’auto reload.
Une autre problématique des MS c’est la distribution de l’identité et de l’accès :
- Première solution, gestion de session dans un redis. Problème les MS appel en permanence le redis (pb réseau) et le redis devient un SPOF.
- Deuxième solution, passer par un proxy applicatif qui fait de l’injection d’identité dans les requêtes HTTP. Pour les développeurs c’est « relou » car il faut le reverse proxy sur le poste de développement. On met du métier dans le proxy, et le code va grossir. et le proxy devient aussi un SPOF. Un proxy est là pour faire le passe plat et être très rapide, pas pour s’occuper d’autres problématiques.
- Troisième solution, les requêtes arrivent directement sur les services qui eux même interrogent une API d’authentification, mais celle ci est quand même un SPOF, de plus c’est lent et difficile à MOCK.
- Bonne solution JWT (distribuer de l’authentification en ayant pas de secret partagé ), Macaroons(Google, distribuer de l’authentification et la déléguer)
Ne pas oublier la maintenance de nos MS. Par exemple certains MS qui ne bougent pas beaucoup, ne seront pas à jour sur leur librairies (faille de sécurité…)
Un des gros avantage des MS, c’est qu’on peut facilement les changer, c’est petit donc facile à faire évoluer car c’est pas très coûteux. On peu jeter du code et e réécrire, voir carrément changer de technologie. Cela permet d’éviter d’accumuler de la dette technique.
Il faut aussi penser à voir du deployment agility, on ne doit pas gérer les machines/VM à la main. Tout doit être automatique.
Et surtout penser au concept de developer happiness. L’architecture et le code doit être cool pour que l’on ait envie de s’en servir, de tester, de faire évoluer etc…
Pattern Matching en Java (10 ?) (Rémi Forax)

On va parler des prochaines features (pattern matching) de Java, talk très spéculatif. Rémy va nous donner un état des lieu de java. Java 9 c’est finit 🙂 (release le 27/07/2017), la réflexion sur java 10 se met en place avec différents projets dont Valhalla (OpenJDK), c’est un projet bien plus ambitieux que les lambdas et les generics, dont les deux principales features sont :
- Value Types
- Generics over primitive and value types
Qu’est ce qui ne va pas avec les objets actuellement? Chaque objet java a un header de 64 bits, même un objet vide prend au minimum 64 bits. Même si maintenant on a beaucoup de RAM, le problème commence quand on a des tableaux d’objets (tableau de référence sur des objets), les coûts d’accès à la mémoire n’ont pas pas beaucoup bougé depuis 1995, donc surtout quand on accède pas au cache, on passe son temps a naviguer de référence en référence et cela coûte cher, car le coût d’accès à la mémoire en rapport avec la vitesse de calcul des CPU n’est plus ce qu’il était, les CPU calcul beaucoup plus vite, cela implique donc énormément de temps perdu dans la navigation de la mémoire. Le modèle des objets ne colle plus à l’architecture des ordinateurs actuels. On crée trop de références, et on fait trop d’allocation et si ça reste (si les objets ne meurent pas vite), on ralenti le GC.
Les value types se base sur l’idée de créer des faux objets, on veut l’écrire comme une classe mais à l’exécution on veut que cela se comporte comme un int (comme une valeur). Ces « trucs » la n’ont pas d’identité, pas d’adresse mémoire. Ils doivent être immuable.
Donc il faut être aussi capable d’écrire une liste de complex (value types), donc on veut un tableau de complex mais pas un tableau de pointeurs sur des complex, pour cela on doit spécialiser le code ce qui est compliqué. Et en prime on pourra donc avoir des ArrayList de int.
Problème, le Bytecode n’est pas prêt pour ça, il n’est pas fait pour qu’on puisse avoir des choses qui soit des objets soit des value type, donc il faut changer complètement le bytecode. Il faut aussi la spécialisation du code à runtime (donc par le JIT pour que cela soit efficace). Et on voudrait que List<?> soit une liste d’objet ou d’autre chose.
Autre projet en cours, le projet Panama, on veut du java qui parle le C par exemple. On va demander au JIT qu’il produise le code qui va faire la liaison du java au C. Et ça fonctionne.
Les objectifs pour les prochaines release de Java sont :
- Java 10 :
- On va inclure panama avec java qui parle le C sans JNI + SIMD/AVX
- valhalla : les value types dans la JVM (features accessible que depuis la JVM pas de Java, on va laisser les autres langages s’appuyant sur la JVM accéder à cette feature pour avoir des retours d’expérience et affiner les choses)
- Java 11 :
- On embarque le full valhalla : value types + specialized generics
Donc on aura pas de nouvelles features pour java 10.
D’ou le projet Amber! Ajouter des features pour inciter les gens à terme à migrer sur Java 10.
Petites features :
- La possibilité de ne pas déclarer les types des variables locales et demander au compilateur de la trouver pour nous. Par exemple :
1var a = 3;
1var list = new ArrayList<String>();
Par contre avec des classes anonymes ce sera plus compliqué, on voudrait que cela soit typé Object et pas NomDeMaClasse$1. Et pour les lambdas cela ne fonctionnera pas (mais comme on met les lambdas dans des méthodes en général plutôt que dans des variables ce n’est pas très grave) - Paramétrer des enums, normalement le type d’une variable de l’enum c’est le type de l’enum alors que dans cette feature chaque variable de l’enum va avoir un type différent.
- Dans Java 9 on ne va plus utiliser le underscore, mais on le remet dans Java 10 (nom de variable qui n’est pas dans le scope, on veut le déclarer mais pas l’utiliser). Le deuxième au niveau des lambdas, on peut pas avoir des paramètres de la lambda qui ont les même nom que les variables locales, même si cela représente la même chose, donc on pourra. Troisièmement, on a laissé des cas d’inférences (le compilateur trouve le type tout seul), quand on a de la surcharge de méthode et que le compilateur ne sait pas quelle méthode utiliser avec les lambda.
Ces petites features ne suffiront probablement pas à inciter les gens à passer sur Java 10. Donc voici la feature qui devrait les y inciter :
- Le Pattern Matching, fonctionnalité demandée depuis 1997 via un switch sur les types :
- Par exemple on définit un objet Json ou JsonArray en Object, et le switch permettra de savoir quel est le type de cet Object.
- De plus techniquement on préférerais que le switch renvoi une expression pas une instruction pour éviter d’avoir besoin d’initialiser la variable. Donc on fera le pattern matching sur des expressions, du coup la syntaxe changera certainement.
- Le default est il nécessaire? Oui parce que le compilateur peut pas garantir que tous les cas sont traités, donc il faut introduire les hiérarchie fermées, j’ai une interface et je liste toutes les classes qui l’implémente. Avec ceci plus besoin de default, le compilateur pourra dire s’il manque un cas dans mon switch.
- Introduction de Data Class (data Point(int x, int y);): avoir la possibilité de définir un regroupement de données et non une classe qui peut être plus complexe. (c’est nécessaire pour les value types)
- Le pattern matching casse l’encapsulation. C’est l’une des raisons conceptuelles pour laquelle le pattern matching n’a pas été introduit en Java.
- Introduction d’un déconstructeur pour sortir les valeurs d’une classe data (équivalent du unapply de Scala).
- Implémentation possible à base de if instanceof … else ce qui n’est pas génial On utilisera plutôt InvokedDynamic pour générer les if else à mesure que les valeurs arrivent à l’exécution. Le code va s’adapter dynamiquement aux variables qui vont être passées.
- Utilisation d’un automate qui n’utilise pas de instanceof. (pas plus lent que Scala) Lorsqu’il y a beaucoup de if, on peut les remplacer par une table de hachage au détriment du inlining et ce quel que soit le nombre de type à matcher, le temps de résolution est constant. Le unapply de Scala alloue 2 objets => très lent.
Comment être Tech Lead dans une pizza team XXL sans finir sous l’eau ? (Damien Beaufils)

Cette session est un retour d’expérience sur un an passé dans une équipe.
L’objectif est de savoir quel rituel et pratiques de développement on peut mettre en place dans une équipe de plus de 10 personne et quel est le rôle du tech lead.
Qu’est ce qu’un tech lead :

Damien est donc arrivé dans une équipe de 10 développeurs (avec les Product Owner, les sponsors…) sur un projet qui avait démarré un an auparavant, avec des cycles itératif de deux semaines. Une équipe de cette taille rend la communication plus complexe, les interactions sont beaucoup plus nombreuses :
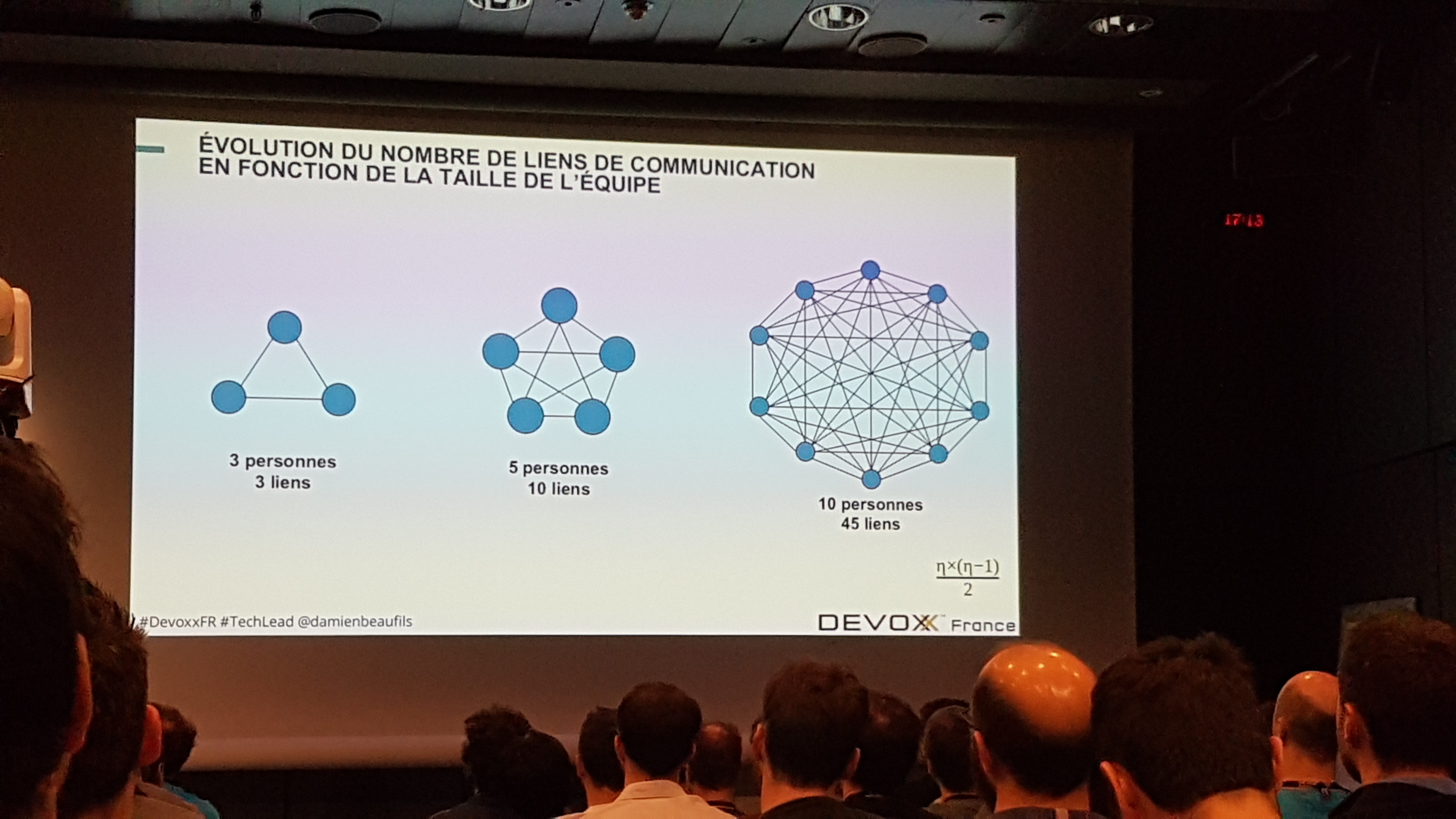
Sa première semaine passée dans l’équipe a consisté à écouter, faire du pair programming, du binômage.
A Rome, comporte toi comme les Romains
L’idée est de ne pas remettre en question les comportements et les façons de faire alors qu’il vient juste d’arriver. Les bonnes comme les mauvaises choses ont des explications dû au passif du projet (timing, pression, turn over etc…)
Cette semaine d’écoute lui a permis d’identifier des signaux faibles :


Ces signaux faibles sont des symptômes, il faut donc aller chercher les causes de cela .
Cette analyse remonte :
- La propriété du code n’est pas collective
- Les pratiques de développement étaient hétérogènes
- Pas de métrique sur la qualité du produit et pas de suivie de celle-ci
Ces trois problématiques seront la pierre angulaire à la mise en place d’amélioration.
La rétrospective technique pour partager les problèmes :

L’idée est de prioriser les sujets, les traiter et si jamais cela prend trop de temps partager en comité plus restreint en dehors de cette réunion.
Il faut aussi mettre en place une table de la loi pour le code. Il faut que cela soit visuel et facile d’accès, cela est privilégié à un wiki qui n’est pas forcément relu.

La revue de code va devenir obligatoire et bloquante si nécessaire. A noter que pour faire de la revue de code cela ne nécessite pas d’être un expert, et cela est avantageux car cela permet homogénéiser le savoir dans l’équipe et partager les douleurs et les techniques.

Et l’avantage de cette propriété collective de code amène :

Cette première pratique a permit de montrer que la propriété du code n’était pas collective et y remédier. Mais les pratiques de dev ne sont pas encore homogénéisées et la qualité du produit n’est ni produite ni mesurée. Que faut-il mesurer? Dans ce cas il a été choisi de mesurer le nombre de tests automatisés et leurs typologies. Pourquoi ce choix?

Après discussion dans l’équipe, ils se rendent compte que personne n’utilisait le même vocabulaire pour parler de test. Donc première action, uniformiser le vocabulaire (qu’est qu’un test unitaire, d’intégration, fonctionnel etc…)

Il a été fait le choix de ne pas mesurer la couverture de test, car ce n’est pas un indicateur de qualité, c’est au mieux un indicateur de non qualité. On peut savoir ce qui n’est pas couvert et regarder dans le code ce que cela peut impliquer. Deuxième raison de ne pas regarder la CU, ne pas tendre le bâton pour se faire battre. Faire des Tests ne doit pas être un objectif, et il faut éviter des débats stériles sur pourquoi la couverture n’est pas plus élevée par exemple.
Après analyse des tests, ils se sont rendus compte qu’il y avait une majorité de tests d’intégration, un tiers de tests fonctionnels, et peu de tests unitaires. Cela donne un indicateur, il n’y a pas une base assez solide de TU. D’où l’approche du TDD (Test Driven Developement). L’équipe sera formé sur cette pratique. Et le tech lead devra remonter les avantages de cette pratique aussi bien aux devs mais aussi aux managers, PO etc… Cette approche fait que e temps de dev augmente légèrement, mais en TMA on passera beaucoup moins de temps à débugger et corriger. Sur le long terme on gagne de l’argent. Les devs sont faciles à convaincre, mais pas les managers.

Les managers proposent donc au tech lead de former un à un les devs sur le TDD. Sauf que si on analyse le temps passé sur chaque personne de l’équipe par de l’accompagnement individuel on se rend compte que cela coûte beaucoup plus cher que une seule formation de trois jours pour toute l’équipe, en gros cela coûte deux fois moins cher. C’est une autre casquette du tech lead, montrer au manager comment une approche de qualité est bénéfique(coût, délai etc…), être l’interlocuteur d’une démarche de qualité aux personnes qui gravitent autour de l’équipe.
Autre point important, faire du one-on-one pour développer un climat de confiance avec les membres de l’équipe. On prend 30mn pour discuter dans une salle. L’objectif est de récupérer de l’information, prendre la température, faire des retours sur le travail accompli, rechercher des axes de progression (augmenter le niveau des personnes) et même déléguer (donc responsabiliser les personnes de l’équipe).
Il faut penser aussi au laquage employé dans l’équipe. Privilégier par exemple l’utilisation de « Le code » plutôt que « Ton code », le code est la propriété collective, et non celle d’un seul dev. (principe Egoless)
Avec ces approches, on tend donc à des pratiques de développement plus homogènes.
Il reste à présent à mettre en place la mesure et le suivie de la qualité du produit.On a commencé à mesurer la proportion des TU, TI et TF. Donc après un peu de temps, on est en mesure de montrer l’évolution de la proportion. Cela permet une certaines transparence., voir ou on est bon ou pas…
Par contre un manager qui voit ces courbes de tests, en tout cas la proportion, se posera forcément la question de la pertinence de TU par rapport à du TF (les TF touchent plus de code, plus de couches et test une fonctionnalité métier…). Donc il faut pouvoir montrer pourquoi les TU sont beaucoup plus rentables que des TF (longs, coûteux, compliqués…)
Montrer l’évolution de la qualité autrement que par la technique :
- Graphe du nombre de fonctionnalité par itération (vélocité)
- Graphe du nombre de bug restant à corriger (plus pertinent que le nombre de bugs corrigés par itération)
- Graphe du nombre de livraison nécessaire par itération (trop de livraison par itération est un facteur de perte de confiance, de stress, de coût)
Damien nous montre que après la formation TDD de l’équipe, les trois métriques évoqués ci-dessus tendent à s’améliorer.
Conclusion :
- L’approche de Damien n’est en rien à copié/collé car son contexte ne sera surement pas le même pour un autre tech lead dans une autre équipe/société
- Chercher à avoir une propriété collective du code grâce à des rituels et des pratiques de partage
- Définir un ou plusieurs aspects de la qualité, les mesurer, les suivre et les afficher
- Faire du coaching et déléguer
Pour finir
Si vous voulez retrouver les conférences filmées du DEVOXX 2017 vous pouvez y accéder sur la chaine Youtube du DEVOXX.