Nous sommes en 2022 et pourtant il existe encore des projets dont les schémas de BDD sont gérés manuellement.
Avec cet article j’espère vous convaincre qu’il est tellement plus simple et pratique d’utiliser un outil comme Flyway ! J’illustrerai le tout avec un exemple d’application Java, des captures d’écran et un repo git.
Problématique initiale
Le besoin de versionning BDD vient du fait que :
- L’évolution d’un projet impliquera systématiquement, tôt ou tard, la modification du modèle de donnée qui l’accompagne. (suite à une nouvelle fonctionnalité par exemple)
- Les livrables projet vont passer par plusieurs environnements intermédiaires avant d’arriver en Production. (ex : Recette / Pré-Production / Production)
Il est donc nécessaire de modifier, pour chaque environnement, le schéma de BDD pour qu’il corresponde à la version de l’application. Action qui nécessite de savoir où on s’est arrêté la dernière fois, (tenir à jour un historique). Et que se passe-t-il si mon collègue responsable de tout ça ne peut pas être présent le jour de la livraison ? Dans certaines entreprises, je n’ai peut être même pas la main sur la BDD et il faudrait passer par une succession de tickets pour laisser des instructions à un administrateur de BDD!
Gérer ces actions manuellement est à la fois laborieux et propice aux erreurs, ce que l’on ne veut pas se permettre et encore moins en Production !
Flyway à la rescousse
Heureusement pour nous, des outils comme Flyway ou Liquibase permettent de répondre à cette problématique et bien plus encore. Penchons nous plus particulièrement sur flyway.
- Flyway se présente comme un outil de migration de données open source axé sur la simplicité et les conventions plutôt que la configuration.
- Il gère les migrations en SQL en étant compatible avec un grand nombre de BDD.
- Il s’interface très facilement à une JVM et expose une API Java qui lui permet de s’exécuter au démarrage d’une application. Il existe aussi en tant que plugin Maven et Gradle.
Maintenant que nous en savons un peu plus, passons à des exemples concrets qui permettrons de répondre aux questions suivantes :
- Comment mettre en place flyway sur une application Java ?
- Comment le versionning de la BDD est-il géré ?
- Que se passe t’il si un script échoue ?
- Comment l’intégrer sur un projet existant ?
- Peut on gérer les changements plus complexes ?
- Peut on rollback vers un version précédente ?
Un premier exemple simple (github)
Mise en place d’une application Java Quarkus
Prenons un simple starter-kit Quarkus/Maven qui nous fournira une application JAVA connecté à une BDD embarquée H2 avec Hibernate, sur lequel nous mettrons en place flyway. Pour créer ce starter kit, on peut télécharger directement le zip du starter ou bien créer directement le projet sur votre repository Github via par le générateur de projets quarkus : https://code.quarkus.io/?e=jdbc-h2&e=hibernate-orm.
La projet ainsi généré contient l’arboresence standard de Maven, pour obtenir le code suivant : github
Il est déjà possible de lancer commande suivante pour exécuter l’application
|
1 |
./mvnw compile quarkus:dev |
1- Configuration de la BDD H2 :
Par défaut, l’application démarre en se connectant à une BDD H2 in-memory.
Pour cet exemple, nous aurons besoin de nous connecter à la base pour lire le contenu des tables (via au choix : un workbench/l’outil database d’intelliJ/la console H2), ce qui n’est pas possible via la configuration in-memory.
Dans le fichier resources/application.properties (configuration de l’application quarkus), ajouter les lignes suivantes:

Quand l’application va démarrer, H2 génèrera un fichier dans » ~/quarkusFlywayDb » et y stockera l’état de la BDD. Ce qui nous permettra de le lire avec un autre outil. (Attention aux utilisateurs de Windows : le fichier est bloqué quand un processus y accède. Il faut donc arrêter l’application pour lire la BDD et vice-versa)
2- Création d’une entité :
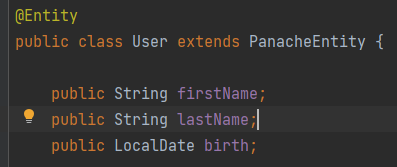
Créons ensuite une entité « User » avec Panache.
Intégration de Flyway
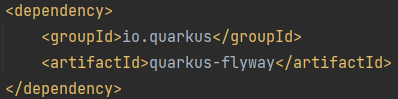
1 – Ajouter la dépendance maven:
Il existe une dépendence « quarkus-flyway » qui est une légère surcouche à Flyway qui permet de s’interfacer plus simplement avec Quarkus (une extension Quarkus). Tout ce qui est faisable avec cette dernière inclus ce qui est faisable avec la version gratuite de Flyway. Ajoutons la dépendence :
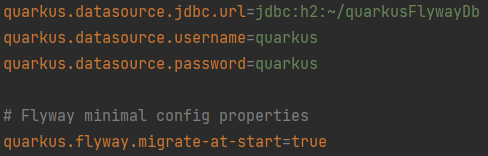
2 – Ajouter la configuration pour activer Flyway :
En ajoutant une simple propriété booléenne dans le fichier application.properties, on obtient :
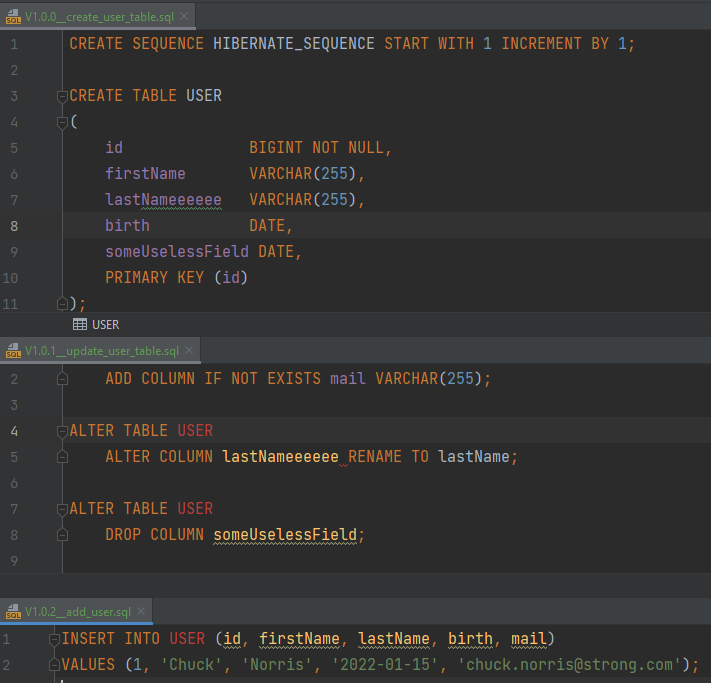
3 – Ajouter des scripts :
Par défaut, flyway va récupérer tous les fichiers présents dans dans le répertoire src/main/resources/db/migration et les exécuter selon leur nommage. La convention de nommage des scripts de migration est la suivante :

On va donc ajouter les scripts suivants qui permettront de tester la création, modification et suppression du modèle de données:
4 – Lancer l’application :
Lançons l’application avec la commande « ./mvn compile quarkus:dev« , on constate que Flyway s’est bien exécuté au démarrage avec les logs suivants :

Les 3 scripts ont bien été pris en compte et joués sur notre BDD et on peut le vérifier en requêtant le schéma de base de données :
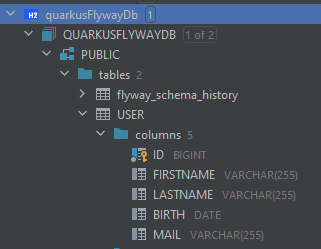
Comment ça marche ?
A sa première exécution on a pu voir (cf capture précédente) que Flyway a créé une table nommée « flyway_schema_history ». Elle contient les données suivantes :

- installed_rank : correspond à l’ordre d’exécution des scripts
- version : la version extraite via la convention de nommage
- description : la description extraite via la convention de nommage
- type : le type du script TABLE/SQL/JDBC
- script : l’emplacement du script
- checksum : séquence propre au contenu du script exécuté
- installed_by : auteur de l’exécution
- installed_on : horodatage de l’exécution
- success: si l’exécution s’est bien déroulée ou non
Rien qu’avec ces quelques colonnes, on comprend la base de fonctionnement de Flyway. Il exécute et historise l’ensemble des scripts, dans un ordre calculé selon leurs nommages. La gestion du modèle de données n’est plus manuelle ! Mais dans les cas particuliers, qu’arrive t’il ?
Comportements d’exécution des scripts
Tous les scripts ont déjà été exécutés
Si on relance l’application flyway détecte que les script ont déjà été joués et ne les exécute pas:

Un script déjà exécuté a été modifié (ajout d’une configuration requise github)
Il est possible qu’un script déjà exécuté soit modifié, mais c’est une erreur puisque cela pourrait générer différents modèles de données par environnement pour une même version de d’application. Il doit y avoir une vérification.
Aucune vérification n’est appliquée, Quarkus la désactive par défaut. Il faut donc rajouter une nouvelle ligne de configuration à notre fichier application.properties :

Au démarrage, Flyway va détecter que le script à changé (via le calcul de checksum) et va remonter une exception, l’application ne démarre pas :
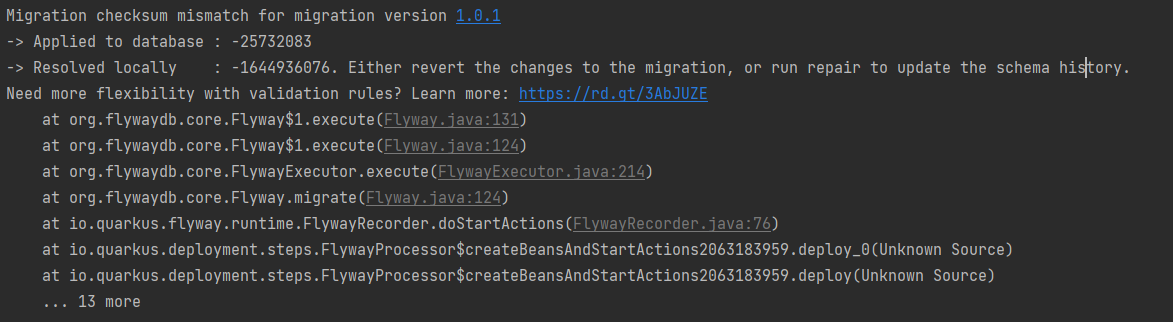
Une intervention manuelle est requise ces changements n’auraient pas dû avoir lieu.
Une bonne pratique est de créer un nouveau script à chaque changement de modèle, on ne modifie pas le dernier script existant. On pourrait se dire qu’on peut modifier les scripts tant qu’ils n’ont pas été livrés sur le premier environnement de la chaîne, mais on rencontrera le même problème entre les différents postes de developpeurs !
L’exécution d’un script a échoué
En introduisant volontairement une erreur dans le script 1.0.1 :
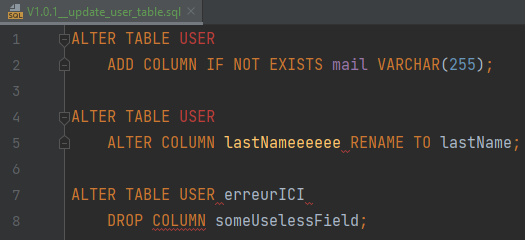
Flyway remonte une exception et l’application s’arrête :

Le script de version 1.0.1 est en success = false et le script 1.0.2 n’a pas été lue par Flyway :

Si je relance l’application, Flyway tentera de repartir de la dernière migration en erreur et de la relancer, la même erreur est remontée. Si je corrige le script et que je le relance, l’application Flyway empêche l’application de démarrer :

Et il a bien raison puisqu’une partie du script peut avoir été jouée (ici les lignes 1 et 4)! Une intervention manuelle est requise.
Si j’utilisais l’outil CLI de Flyway je pourrais utiliser la commande « repair ». Mais on va pouvoir faire l’équivalent directement sur la table flyway_schema_history !
Il suffit de supprimer la ligne en question. De façon générique :

En cas de problème, on a toujours la main sur flyway via sa table !
Intégration à un projet existant (github)
Il est possible d’intégrer Flyway sur une application dont le modèle de données existe déja, le comportement doit être double :
- Pour un environnement avec un schéma de structure X, Flyway doit seulement créer la table « flyway_schema_history » et gérer les futurs scripts Y.
- Pour un futur environnement, Flyway devra créé la structure X avant de jouer les scripts Y.
Il faut d’abord extraire la structure du schema actuelle avec un outil quelconque et l’ajouter dans un script associé à la baseline-version choisie (ici V0.0.0):

Il reste alors à ajouter 2 lignes de configuration pour définir cette migration qui correspondra à la baseline :

Avec une schéma vide, les 2 scripts sont bien jouées :

Avec une schéma non vide, le premier script est sauté et le deuxième est joué !

Migration programmatique (github)
Il se peut qu’un simple script SQL ne réponde pas complètement à votre besoin. Il est possible de les gérer via du JAVA ! Pour cela, 2 prérequis :
1- Le fichier Java doit se trouver dans le package db.migration:
2 – La migration Java doit implémenter la classe JavaMigration (Il existe une implémentation de base nomée BaseJavaMigration). A partir de là tout est faisable :
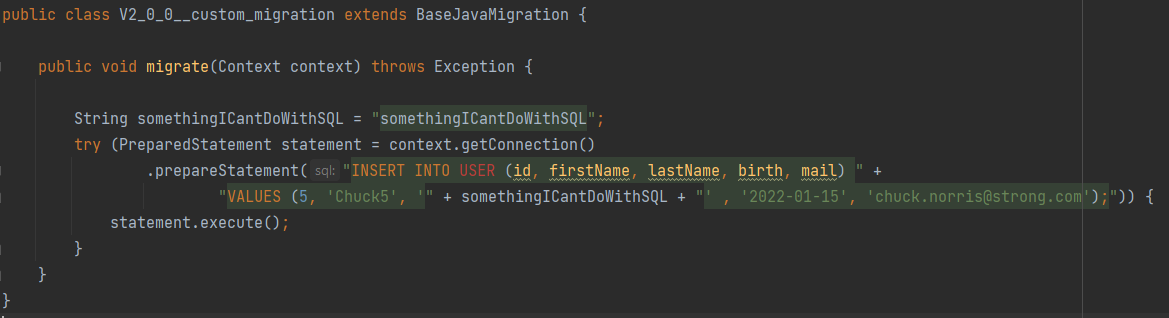
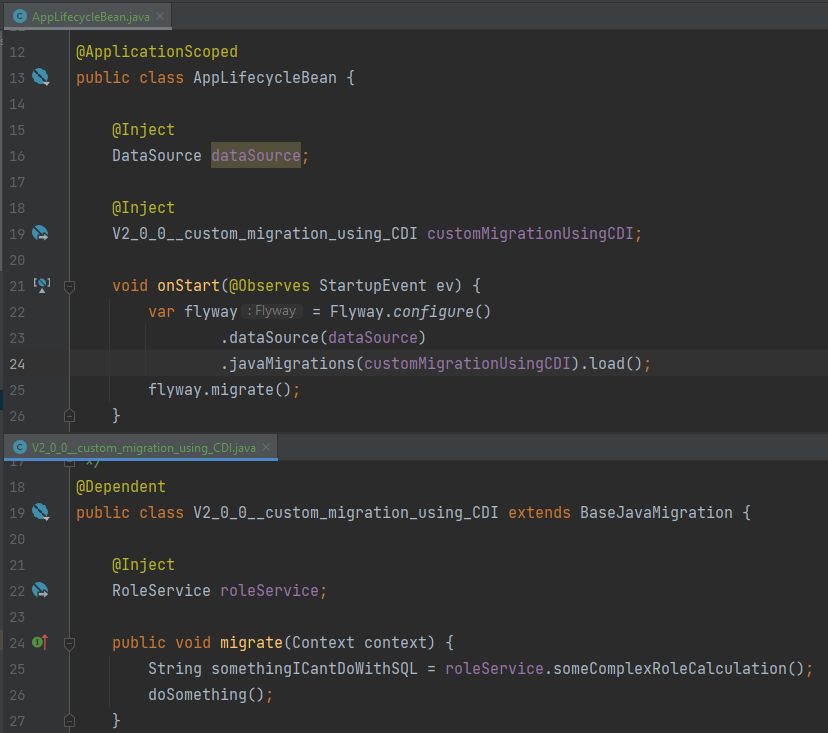
Attention, Flyway ne prend pas en compte les injections de dépendance par défaut. Pour contourner cela, on peut lancer manuellement Flyway au démarrage de l’application en lui Injectant les migrations Java :
Autres fonctionnalités utiles mais payantes
Toutes les fonctionnalités que nous avons vu jusqu’ici était comprises dans la version « community » de Flyway. Elles doivent suffire pour de petits et moyens projets.
Voici quelques fonctionnalités de la version « Teams » qui me semblent particulièrement intéressantes :
- La possibilité de rollback d’un version à une version précédente, chaque script VX_script.sql aura un script de « rollback » associé RX_script.sql.
- Simuler l’application des script et les prévisualiser. Permet de rajouter une étape de validation manuelle avant d’appliquer les modifications.
- Possibilité de migrer des scripts « .sh, .bash, .py, .cmd …«
- Au fil du temps et des évolutions, les scripts vont s’entasser. Il est possible de changer la baseline qui deviendra un seul fichier contenant le modèle actuel.
Conclusion
Le coût de mise en place de flyway est quasi-inexistant quelque soit la vetustée du projet dans lequel on l’insère. Sa version community fourni un ensemble de fonctionnalités suffisant pour la plupart des besoins que j’ai pu rencontrer.
Ce qui fait de Flyway un outil incontournable à mon sens pour tout projet dépendant d’une BDD vouée à évoluer au fur et à mesure des développements, en somme 99,9% des projets 🙂 !