Après une version 7.x dont la première version commençait à dater (avril 2019) et après 17 versions mineures, la version 8.0 de la stack Elastic a enfin été release le 10 Février 2022, suivie de la version 8.1 dès le 8 mars 2022.
C’est donc l’occasion pour nous de se pencher sur ce qu’apporte cette nouvelle version majeure attendue depuis longtemps, mais avant tout, qu’en est-il de la migration depuis la version 7.X?
Migration vers la version 8.X
La version 7.17 sera maintenue jusqu’en Août 2023 ce qui laisse le temps de mettre à jours vos clusters d’autant plus que la première fonctionnalité mise en avant par la version 8.0 est sa rétrocompatibilité avec les APIs 7.X à l’aide d’entêtes HTTP.
Activer la rétrocompatibilité
Pour l’activer , la variable d’environnement ELASTIC_CLIENT_APIVERSIONING doit être configurée à true et les clients (migrés à la derniere 7.X disponible, soit la 7.17 au 11/03/22) s’occupent du reste.
Dans les faits, cela se traduit par l’ajout des entêtes suivants aux requêtes vers votre cluster :
|
1 2 |
Accept: "application/vnd.elasticsearch+json;compatible-with=7" Content-Type: "application/vnd.elasticsearch+json;compatible-with=7" |
L’entête Accept est obligatoire et l’entête Content-Type est nécessaire uniquement si un corps est fourni avec la requête.
Ainsi, un client en version 7.X peut requêter un cluster en version 8.0 et obtenir des réponses au format 7.X.
A noter : l’utilisation d’une API dépréciée en 8.X déclenche tout de même l’écriture d’un message d’avertissement et l’utilisation de ces headers permet ainsi de retrouver dans les logs la liste des appels à modifier avant de pouvoir sereinement monter de version.
Voyons maintenant ensemble quelles sont les autres fonctionnalités et changements importants introduits par la branche 8.X d’Elasticsearch.
Sécurité activée par défaut (8.0)
Sûrement l’un des plus gros changements apportés par cette nouvelle version majeure, Elastic a également fait le choix d’activer par défaut plusieurs mécanismes de sécurité, contrairement aux versions précédentes où cela nécessitait une activation explicite, tout en automatisant au maximum le processus.
Ainsi, au premier démarrage d’un cluster :
- Les clés et certificats nécessaires pour activer TLS pour les couches HTTP et Transport sont générés
- La configuration TLS est écrite dans le fichier de configuration
elasticsearch.yml - Un mot de passe est généré pour l’utilisateur
elastic
Pour faciliter la connexion de Kibana et de nouveaux noeuds au cluster, un token d’inscription (valable 30mn) est également généré.
Fidèle à sa volonté de faciliter l’onboarding, Elasticsearch vous proposera un résumé de cette étape dans les logs au premier démarrage où l’on retrouve les éléments détaillés ci dessus :
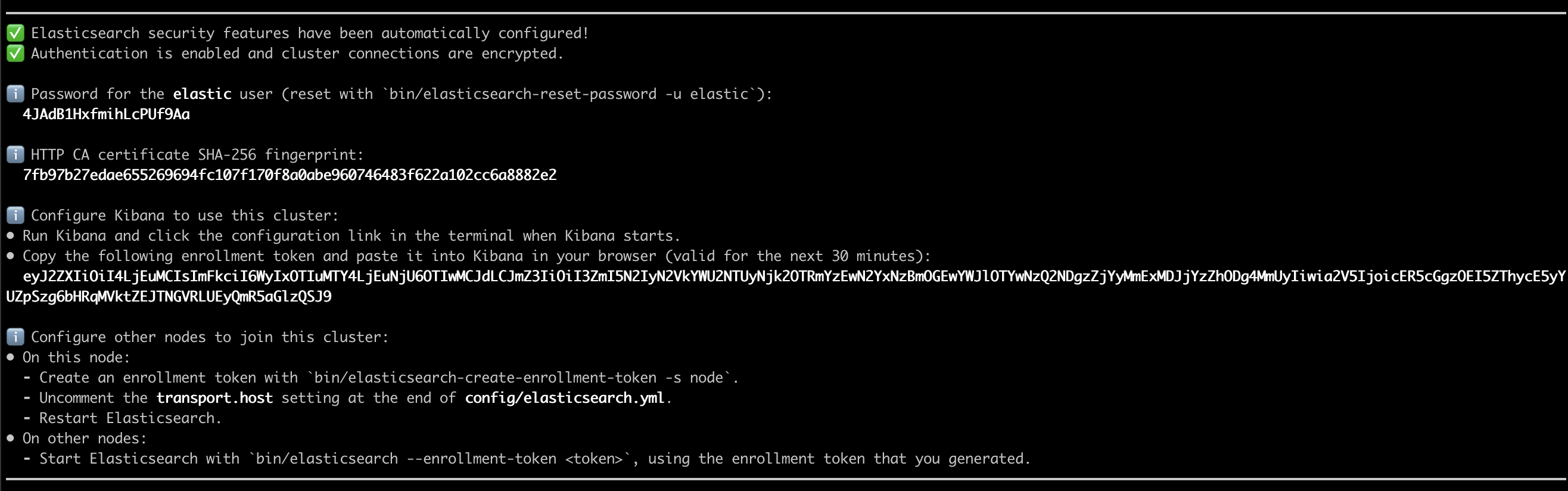
On y voit notamment le mot de passe généré pour l’utilisateur elastic (attention à ne pas le perdre!) ainsi que le token d’inscription généré, qui est utilisé au démarrage de Kibana et doit être entré sur la page dont l’URL est fournie dans les logs de démarrage de Kibana :

En bref, la mise en place de la sécurité est grandement facilitée par rapport aux procédures manuelles de la version 7.X et c’est assurément un pas dans la bonne direction.
Intégration de modeles PyTorch pour le traitement du langage naturel (8.0)
Elasticsearch se prête particulièrement au traitement du langage naturel (NLP) et la version 8.0 apporte la possibilité d’importer directement dans son cluster des modèles PyTorch. Ceux ci peuvent ensuite être utilisés pendant la phase d’ingestion pour un ensemble de tâches spécifiques (qui sera étendu dans le futur) :
- Named Entity Recognition (NER): extraction automatique d’entités (personnes, organisations, dates, email etc.)
- Fill-mask : complétion de termes masqués dans un contexte précis
- Text classification : utilisé notamment pour l’analyse de sentiments (POSITIVE/NEGATIVE) en se basant sur les termes utilisées
- Zero-shot classification (classement sans entrainement spécifique préalable)
- Text embedding
Il est donc à présent possible d’importer un modèle téléchargé depuis Hugging Face et de l’utiliser dans une pipeline d’ingestion pour de l’analyse de sentiments ou de la classification en quelques clics.
Si le sujet vous intéresse particulièrement, je vous invite à visionner l’excellent webinar (présenté par Josh Devins d’Elastic) qui est consacré justement à l’intégration du NLP dans la stack Elastic.
Recherche approximative des k plus proches voisins (ANN) (8.0)
La recherche vectorielle est un sujet qui prends de plus en plus d’importance dans Elasticsearch depuis l’introduction du type de champ dense_vector dans la version 7.0 du moteur de recherche.
Quelques mots sur la recherche vectorielle
Une présentation complète de la recherche vectiorelle est en dehors du scope de ce billet, mais nous pouvons expliquer en quelques mots l’interêt de pouvoir utiliser les vecteurs stockés dans nos documents.
La recherche classique se base sur la présence (ou non) de termes passés par l’utilisateur au moment de sa requête. Un désavantage de ce fonctionnement vient du fait qu’un document peut être omis parce qu’il ne contient pas l’un des termes de la requête alors qu’il serait pertinent.
Les moteurs de recherches modernes cherchent à contourner ce problème en se basant sur la similarité sémantique avec les termes de recherche, plutôt qu’une égalité stricte, à l’aide de plongements textuels (text embeddings).
Les plongements textuels sont la représentation d’un mot (plongement lexical) ou d’une phrase (plongement de phrase) sous forme de vecteur numérique. L’idée derrière ces représentations est que 2 mots dont le sens est proche doivent avoir des vecteurs numériques proches. On peut donc trouver des correspondances avec des documents en se basant plus sur la sémantique, de manière à mieux appréhender le contexte de la requête.
Pour approfondir le sujet dans le contexte Elasticsearch, je vous invite à consulter le post de blog consacré à la recherche de similarités textuelles grâce aux champs vectoriels sur le site d’Elastic.
API _knn_search
Les versions 7.3 et 7.4 introduisaient des fonctions de calcul de distance permettant, à l’aide d’une requête script_score, d’influer sur le score par similarité. La version 8.0 va plus loin avec cette fois l’introduction d’une API dédiée à la recherche des k plus proches voisins, basée sur l’algorithme HNSW.
S’agissant d’une version approximative de la recherche kNN, les résultats ne seront pas aussi précis qu’une recherche kNN basée sur script_score, mais les performances sur des gros corpus de documents sont bien meilleures d’après la documentation.
Amélioration des performances (8.0)
Dans la lignée de la version 7.x, la version 8.x comporte son lot d’améliorations concernant les performances et la consommation de ressources.
Espace disque
Les structures de données utilisées pour stocker les données sur le disque ont été mises à jour de manière à optimiser la consommation d’espace-disque pour les champs de type keyword, match_only_text et text (dans une moindre mesure). Le gain mesuré globalement reste faible en pourcentage (3,5% d’après Elastic) mais au vu des volumes parfois mis en jeu, cela reste non négligeable.
Vitesse d’indexation
Cette version apporte une amélioration de la vitesse d’indexation des structures utilisées pour les champs geo_point, geo_shape, and xxx_range. Les gains annoncés sont de l’ordre de 10 à 15% au niveau de Lucene, ce qui s’avèrera notable si des documents comprennent une majorité de champs de ce type.
La version 8.1 a été mise à disposition très rapidement et comporte surtout des corrections de bugs, mais quelques fonctionnalités interessantes ont également été embarquées.
Recherche dans les champs de type doc-value-only (8.1)
Les doc values sont une fonctionnalité présente depuis longtemps dans Elasticsearch (depuis la 1.0!) et active par défaut.
Pour rappel, il s’agit d’une structure de données générée à l’indexation et stockée sur le disque au lieu d’être montée en mémoire (comme les index inversés). Elle permet de libérer de la mémoire au prix d’une consommation d’un peu plus d’espace disque, et d’un léger impact sur les performances lors des opérations de tri et d’agrégations (tempéré par le fait que ces fichiers peuvent être mis en cache par l’OS) où elles sont utilisées.
Depuis la version 8.1, cette structure de donnée peut également être requêtée (au prix de performances bien moindres) ce qui peut s’avérer utile pour des champs qui ne sont pas requêtés souvent ou si la performance n’est pas primordiale.
Par exemple, créons l’index suivant en version 7.X et en version 8.1 :
|
1 2 3 4 5 6 7 8 9 10 11 |
PUT /test { "mappings": { "properties": { "docvalue-only":{ "type": "keyword", "index": false } } } } |
Ajoutons y un document très simple comprenant un champ keyword non-indexé :
|
1 2 3 4 |
PUT test/_doc/1 { "docvalue-only": "Tolkien" } |
Si l’on effectue la recherche suivante :
|
1 2 3 4 5 6 7 8 |
POST test/_search { "query": { "match": { "docvalue-only": "Tolkien" } } } |
On obtiens en 7.X une erreur indiquant que le champ n’est pas recherchable puisque non-indexé
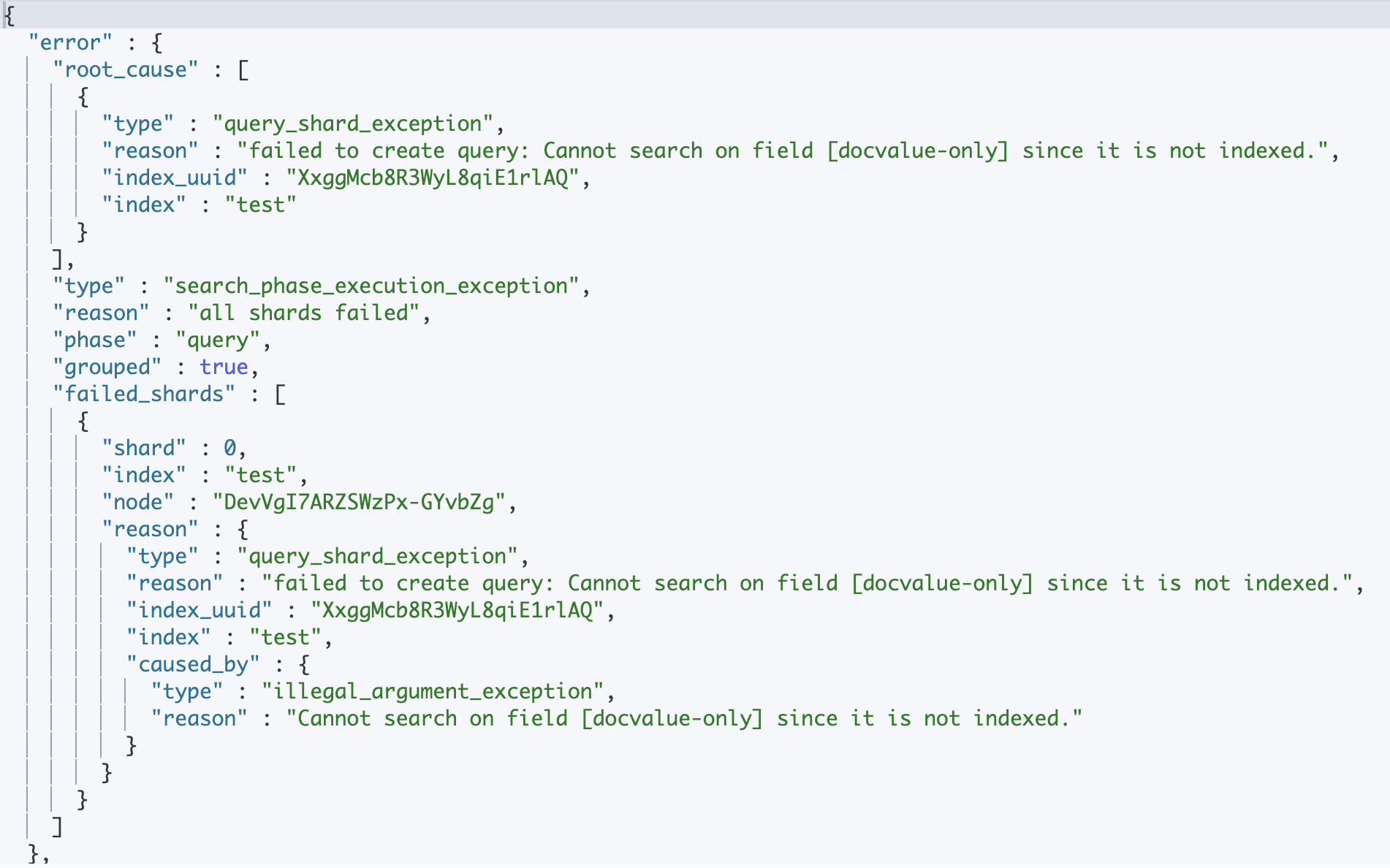
En 8.1, on retrouve notre document, avec certes un temps de réponse plutôt élevé (a noter, la même recherche s’effectue en 1ms une fois puisque le document est mis en cache)

Agrégation géographique hexagonale (8.1)
Une nouvelle agrégation permettant d’agréger vos résultats selon leur position géographique a été introduite. Contrairement aux agrégations geohash et geogrid, la grille utilisée n’est pas basée sur des cellules carrées mais hexagonales, cette agrégation s’appuyant sur H3 (développée par Uber).
Une visualisation correspondante est prévue à l’avenir pour Kibana.
Nouvelle syntaxe d’accès aux champs dans les scripts Painless (8.1)
Accéder à la valeur d’un champ d’un document dans un script Painless obligeait à passer par la variable doc et à vérifier à la fois que le champ et sa valeur existait.
En 8.1, une nouvelle API est introduite pour simplifier cela : il s’agit de l’API field.
Si l’on reprends l’exemple du document précédent et qu’on veut récupérer la valeur du champ docvalue-only pour le passer en majuscule :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
POST test/_search { "query": { "match_all": {} }, "script_fields": { "uppercased": { "script": { "lang": "painless", "source": """ String value = ""+ doc['docvalue-only']; return value.toUpperCase(); """ } } } } |
On obtiens le résultat attendu :

Cependant sans vérification particulière sur l’existence du champ et de sa valeur, on rencontre une erreur dans l’un ou l’autre cas, nous forçant à écrire d’encombrantes vérifications à chaque fois :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "script": { "lang": "painless", "source": """ if(doc.containsKey('unknown-field') && !doc['unknown-field'].empty){ String value = ""+ doc['unknown-field']; return value.toUpperCase(); } return 'NO-VALUE'; """ } } |
Avec la nouvelle API field, on peut remplacer cela par la requête suivante et obtenir le même résultat de manière bien plus lisible (en particulier avec le raccourci $) :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
POST test/_search { "query": { "match_all": {} }, "script_fields": { "uppercased": { "script": { "lang": "painless", "source": """ String value = ""+ $('unknown-field', 'no-value'); return value.toUpperCase(); """ } } } } |
Et le résultat attendu (la valeur par défaut) est obtenu à la place d’une erreur :

A noter : cette fonctionnalité est toujours en beta et n’est donc pas utilisable pour tous les types de champs (notamment les champs de type text).
Conclusion
En résumé, nous avons pu voir les apports majeurs de cette nouvelle version de la stack Elastic à Elasticsearch. Bien entendu, cette liste n’est pas exhaustive et ne couvre pas les autres produits de la stack, mais on peut déjà se réjouir de la simplification apportée au processus de sécurisation d’un cluster et à l’importance que prends le traitement du langage naturel dans le moteur de recherche.
Chez Sedona, nous attendons avec impatience de voir le reste de ce que cette branche 8.X nous réserve, et nous ne manquerons pas de vous faire part de nos prochains coups de coeur.