
Introduction
L’événement Scaling GKE with partners s’est récemment déroulé, mettant en lumière l’exécution de charges de travail IA/ML sur Google Kubernetes Engine (GKE). Cette journée immersive a offert une plongée approfondie dans l’écosystème en constante évolution de l’intelligence artificielle et de l’apprentissage automatique, ainsi que dans le rôle central joué par GKE dans cette transformation.
Cet événement a permis de comprendre les raisons qui poussent de nombreux clients à choisir GKE pour leurs projets d’IA/ML. À travers de présentations, de démonstrations et de discussions avec des experts et des partenaires, les avantages de GKE ont été clairement mis en évidence, sans recours à une rhétorique commerciale excessive.
Dans cet article, nous examinerons les moments forts de cet événement, les leçons clés tirées de ces discussions, ainsi que les perspectives intrigantes sur l’évolution de l’IA/ML sur GKE. Suivez cette rétrospective de « Scaling GKE with partners » pour découvrir comment GKE continue de repousser les limites dans ce domaine passionnant.
Jeudi 22 Février 2024
Le Matin
Welcome and Intro
par Gabriel Bechara (Partner Engineer), Nael Fridhi (AppMod Specialist), Guillaume Morini (AppMod Specialist)
Nous avons été accueillis au siège de Google France. Tout d’abord nous avons eu droit à une petite introduction sur « Generative AI Studio » qui est un outil de console Google Cloud permettant de créer rapidement des prototypes et de tester des modèles d’IA générative. Vous pouvez tester des exemples d’invites, concevoir vos propres invites et personnaliser les modèles de base pour gérer les tâches qui répondent aux besoins de votre application.
Ensuite, nous avons eu la présentation du plan du jour :

Building a scalable AI and ML platform with Google Kubernetes Engine (GKE)
par Gari Singh, Product Manager (GKE), Google Cloud
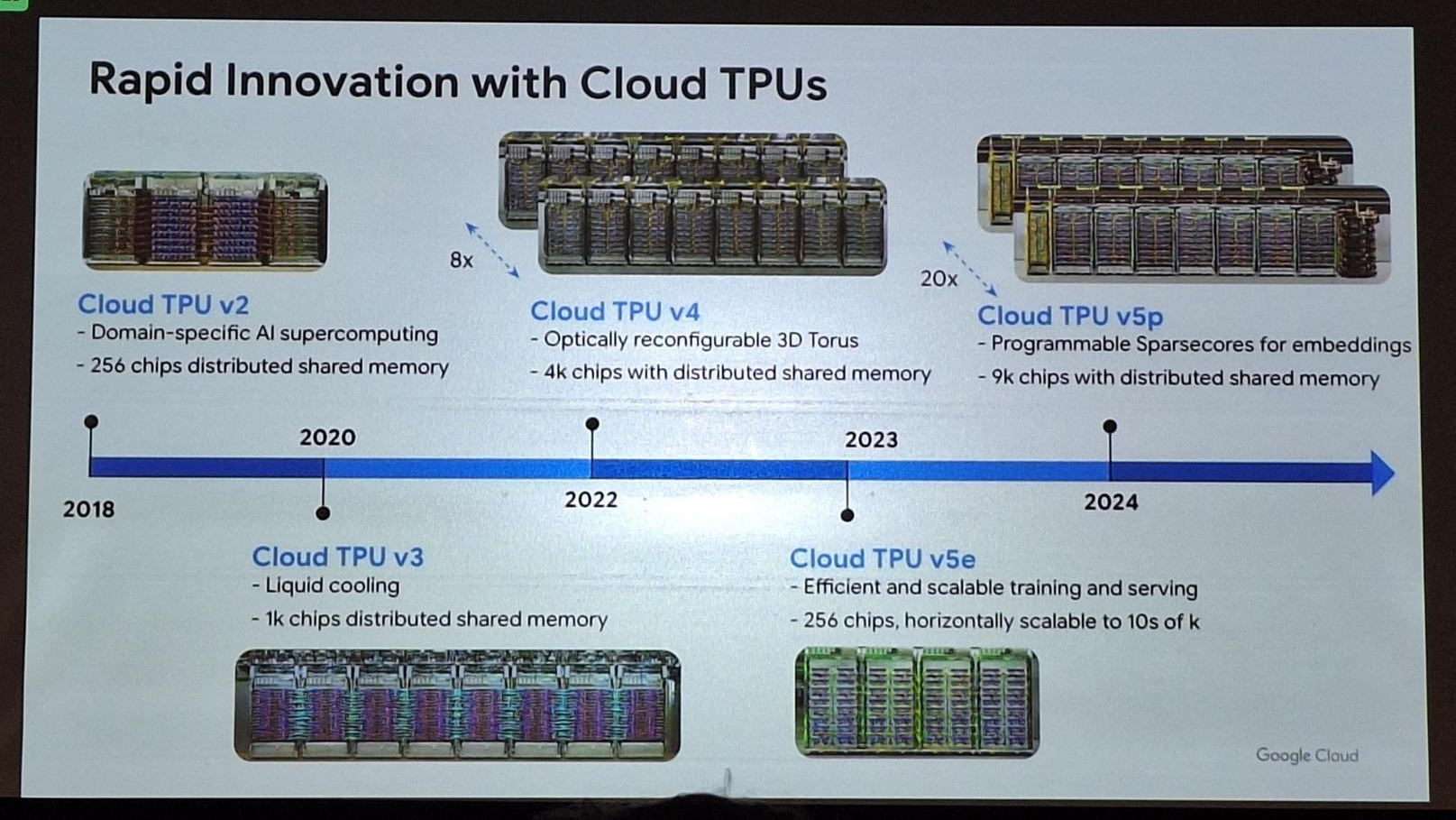
Une récente présentation a mise en lumière la création d’une infrastructure robuste pour l’IA et le ML. L’accent a été porté sur l’évolution rapide des modèles d’IA générative et l’importance croissante des modèles ouverts pour favoriser l’innovation. Les défis majeurs rencontrés dans ce domaine incluent l’accès aux ressources matérielles et l’optimisation des performances et des coûts.
Une stratégie clé consiste à utiliser Kubernetes comme fondation pour les infrastructures d’IA. Cette approche offre flexibilité, performances et efficacité, en permettant notamment d’orchestrer des modèles d’IA à grande échelle et d’optimiser l’utilisation des ressources informatiques.
L’utilisation de Google Kubernetes Engine (GKE) comme infrastructure cloud native présente des avantages significatifs en termes de mise à l’échelle, de performances et de coûts. Des solutions telles que Kueue pour la gestion des tâches et des ressources, ainsi que des outils de planification dynamique, sont également mises en avant pour optimiser les opérations.
Enfin, l’importance d’une plateforme unifiée pour l’IA et le ML a été soulignée, mettant en évidence les options matérielles variées disponibles sur Google Cloud et l’engagement continu de Google en matière d’innovation dans ce domaine.
Reference Architecture of an ML Training Platform on Kubernetes
Par Ali Zaidi, Solutions Architect, Google Cloud
La présentation a détaillé l’architecture d’une plateforme d’entraînement en Machine Learning (ML) sur Kubernetes, mettant en avant l’intégration de Kueue (https://kueue.sigs.k8s.io), un système de gestion de files d’attente de tâches spécialement conçu pour Kubernetes. Cette plateforme vise à faciliter une gestion précise des tâches et une allocation efficace des ressources.
L’intégration de cette architecture à la Plateforme de Traitement par Lots sur Google Kubernetes Engine (GKE), comme décrite dans le référentiel (https://github.com/GoogleCloudPlatform/ai-on-gke/blob/main/gke-batch-refarch), a été soulignée, offrant ainsi un environnement extensible pour l’entraînement en ML. La gestion intelligente des charges de travail et l’utilisation stratégique des ressources VM ont été mises en avant pour garantir une utilisation optimale des ressources, tout en répondant aux diverses priorités des équipes de développement.
Kueue a été identifié comme un composant central de l’orchestration des ressources et de la planification des tâches au sein de la plateforme, permettant une distribution équitable des ressources et une exécution efficace des tâches.
Enfin, le processus de déploiement simplifié grâce à des scripts Cloud Build et Terraform, ainsi que la surveillance de la santé de la plateforme assurée par Prometheus et Grafana, ont été présentés comme des éléments cruciaux de cette architecture.
En résumé, cette présentation a souligné la flexibilité et la puissance de Kubernetes et de GKE dans le domaine de l’entraînement en ML, offrant ainsi un modèle performant et rentable pour répondre aux besoins croissants de traitement de données dans un environnement cloud-native.
Pause déjeuner

L’après-midi
Working with scarce resources – GPU, TPU, Spot obtainability
Par Maciek Rozacki, Product Manager, GKE
Dans le domaine de l’informatique « cloud », des idées préconçues sont souvent véhiculées, telles que de croire que les ressources sont infinies. Cependant, cette perception est souvent loin de la réalité. De même, beaucoup pensent que les accélérateurs comme les GPU et les TPU sont toujours en rupture de stock, ce qui peut décourager leur utilisation. Pourtant, une réévaluation de ces croyances révèle des opportunités insoupçonnées.
Une autre idée fausse répandue est que la structure des centres de données est trop complexe pour une utilisation efficace des GPU, conduisant à sous-estimer leur fiabilité par rapport aux CPU. Cependant, cette perspective néglige les avancées significatives dans la gestion des ressources informatiques. De plus, certains peuvent considérer l’accès aux GPU comme rare et difficile à obtenir, mais des solutions innovantes émergent pour répondre à cette demande croissante.
Dans ce contexte, les fonctionnalités de partage des ressources proposées par des plateformes telles que GKE deviennent essentielles. En permettant le partage de GPUs entre plusieurs instances, l’adoption de services multi-processus et le développement de mécanismes de partage temporel, GKE offre des solutions pragmatiques pour optimiser l’utilisation des ressources limitées dans le cloud. Ces approches révolutionnaires ouvrent la voie à une utilisation plus efficace et équitable des accélérateurs, contribuant ainsi à démocratiser l’accès à ces technologies de pointe.
Labs time: selection on labs on training, fine-tuning and serving open source models on GKE
Le lab proposé se concentre sur l’utilisation des fonctionnalités d’orchestration fournies par Google Kubernetes Engine (GKE) pour le déploiement de modèles de langage de grande envergure (LLMs).
Au cours de cette expérience collaborative, les participants sont guidés à travers plusieurs étapes :
- Clonage d’un référentiel GitHub renfermant le code nécessaire.
- Création d’un cluster GKE Autopilot pour héberger le déploiement.
- Examen attentif des manifestes de déploiement afin de comprendre les spécifications requises.
- Vérification régulière de l’état d’avancement de la création du cluster pour garantir un processus sans accroc.
- Déploiement du modèle Falcon 7B selon les directives fournies.
- Interaction avec le modèle déployé via une application de chat web exploitant Gradio pour une expérience utilisateur optimale.
Cette expérience pratique permet à l’ensemble des participants d’explorer les tenants et aboutissants du déploiement et de la gestion de modèles de langage de grande envergure sur GKE. En suivant méthodiquement ces instructions, ils acquièrent une compréhension approfondie des capacités offertes par cette plateforme, tout en se familiarisant avec les défis et les opportunités inhérents à ce domaine en constante évolution.
Conclusion
En conclusion, l’événement a démontré de manière convaincante l’importance croissante de Google Kubernetes Engine (GKE) dans le domaine de l’intelligence artificielle et de l’apprentissage automatique (IA/ML).
À travers des présentations et des discussions approfondies, les avantages de GKE pour ces charges de travail ont été clairement mis en évidence, sans recourir à une rhétorique commerciale excessive. En mettant l’accent sur la flexibilité, les performances et l’efficacité de l’utilisation de Kubernetes comme fondation pour les infrastructures d’IA, l’événement a souligné les avantages significatifs que GKE offre en termes de mise à l’échelle, de performances et de coûts.
De plus, l’architecture de référence présentée pour une plateforme d’entraînement en Machine Learning sur Kubernetes a mis en lumière l’importance de la gestion précise des tâches et de l’allocation efficace des ressources, tout en soulignant l’orchestration des ressources et la planification des tâches grâce à des outils tels que Kueue. Les discussions ont également abordé la question de l’utilisation efficace des ressources rares telles que les GPU et les TPU, soulignant les opportunités offertes par des plateformes comme GKE pour optimiser leur utilisation.
Enfin, les sessions pratiques ont permis aux participants d’explorer concrètement le déploiement et la gestion de modèles de langage de grande envergure sur GKE, offrant ainsi une compréhension approfondie des capacités de la plateforme.
En résumé, l’événement a souligné le rôle crucial de GKE dans l’évolution de l’IA/ML, fournissant aux participants une vision claire des avantages, des défis et des opportunités dans ce domaine en constante évolution.