Cette année encore, Sedona était présent au SymfonyLive Paris, représentée par Guillaume, Stéphane et Jean, avec pour la première fois un petit passage sur scène où Jean a présenté lors d’un lightning talk son travail avec l’Observatoire de Paris.

Pour ceux qui n’étaient pas présents, Guillaume nous a fait un résumé complet des différentes conférences :
Dépôt monolithique avec git
Par Fabien Potencier
La notion de répertoire monolithique est utilisée par Facebook et Google, qui pourtant ont des dizaines de gigas de données de code.
Symfony a choisi de les imiter, ils ont donc centralisé tous les repository des projets sous un même dépôt sous github. Idéal pour les applications en micro-services.
Avantages :
- Réutilisation de code : les bundles développés peuvent être réutilisés sans duplication sur tous les projets
- Corrections en une seule pull request : les correctifs apportés sont déployés sur tous les projets en une seule demande
- Contrôle d’accès : l’accès à tous les répertoires peuvent être autorisés en une fois
- Intégration continue : les tests unitaires et fonctionnels sont faits sur tous les projets
Inconvénients :
- Contrôle d’accès : impossibilité de différentier les droits d’accès aux différents projets (pour les prestataires intervenant sur seulement certains projets)
Découplage par repository
Il a donc décidé d’allier gestion monolithique sur plusieurs répertoires. Les bundles communs sont partagés et les traitements spécifiques sont isolés. Pour cela, il utilise git sub-tree qui permet de séparer un grand repository en plusieurs plus petits.
Le code est ainsi modulable pour le développement si le développeur ne doit pas avoir droit d’écriture sur la totalité du code et le déploiement pour appliquer les correctifs sur différents projets.
La recette en revanche peut être faite sur le code en intégralité ce qui permet de tout tester simultanément.
Ce procédé conserve donc les avantages du répertoire monolithique et le code est séparé en plusieurs repos via git sub-tree split.
http://www.git-attitude.fr/2015/01/30/git-subtrees/
Guard dans la vraie vie
(par Jeremy)
https://speakerdeck.com/jeremyfreeagent/guard-dans-la-vraie-vie
GuardBundle est un composant d’authentification disponible à partir de la version 2.8 de Symfony. Il permet de regrouper les 3 ou 4 classes à mettre en place habituellement (AuthenticationProvider, Listener, SecurityFactory) en une seule mais n’apporte pas plus de fonctionnalités d’authentification. Il simplifie également son utilisation qui est souvent compliqué car divisé en plusieurs services.
L’implémentation de l’interface GuardAuthenticatorInterface qui étend l’interface AuthenticationEntryPointInterface définissant la fonction start() qui permet de lancer la connexion. Son implémentation permet de centraliser les besoins d’authentification via les formulaires de connexion, Facebook, Twitter ou tout autre service basé sur OAuth, jetons API, etc. Ils sont paramétrés dans le fichier security.yml sous le terme authenticators et celui par défaut est ciblé par entry_point.

Récupérable via composer require sensiolabs/connect
Les fonctions disponibles :

- getCredentials() : renvoie les références de l’authentification (login, password, apikey)
- getUser() : renvoie l’utilisateur identifié par les références
- checkCredentials() : vérifie que les références d’un utilisateur sont valides
- createAuthenticatedToken(UserInterface$user,$providerKey) : crée un token d’authentification à l’utilisateur
- onAuthenticationSuccess : traitement en cas de connexion réussie
- onAuthenticationFailure : traitement en cas d’échec d’authentification
- start() : lance le formulaire de connexion
- supportsRememberMe() : pour les cookies liés à l’option de sauvegarde des infos de connexion
http://symfony.com/blog/new-in-symfony-2-8-guard-authentication-component
R2D2 to BB8
(par Vincent CHALAMON)
http://fr.slideshare.net/VincentCHALAMON/r2d2-to-bb8-60662855
Dans le cadre du site Internet LaFourchette, les équipes dédiées ont été amenées à migrer l’application de Symfony2 (symbolisé par R2D2) à Symfony3 (BB8) car la dette technique était trop importante et les mises à jour étaient devenues compliquées.
Mais vu l’ampleur de la tâche, qui est prévue sur plusieurs mois, voire années, il était nécessaire de faire une migration continue.
Pour cela, ils ont définis des priorités dans l’évolution des fonctionnalités et doivent donc faire cohabiter l’ancienne version et la nouvelle avec synchronisation des données.
Ils ont choisi comme outil :
- apiPlatform pour la gestion des apis.
- Behat pour les tests
- PHPUnit pour les tests unitaires
- Doker comme environnement
- Et composer, TwGit, Scrutinizer
Après calcul, ils se sont rendus compte que la migration des données prendrait 9 jours et ils ne pouvaient pas se permettre un tel arrêt de service, ils ont donc opté pour de la migration continue.
Pour la cohabitation des 2 applications, ils ont utilisé le LegacyBundle qui sera supprimé en fin de migration. 3 phases pour synchroniser les 2 bases de données :

Loaders : PDO (à la place de doctrine)
Pour migrer en continue les données d’une base à l’autre, un loader est mis en place pour chaque entité et priorisé. Ils sont lancés via des commandes (console) à des heures creuses.
Doctrine étant trop gourmand en performance, PDO a été choisi pour assurer les transactions avec les 2 bdd. De plus l’absence de Doctrine leur permet de faire des requêtes SQL trop compliqué pour un ORM.
Seules les informations nécessaires sont importées (MVP) pour ne pas surcharger inutilement la nouvelle base et la gestion des doublons et des erreurs doit être anticipée.
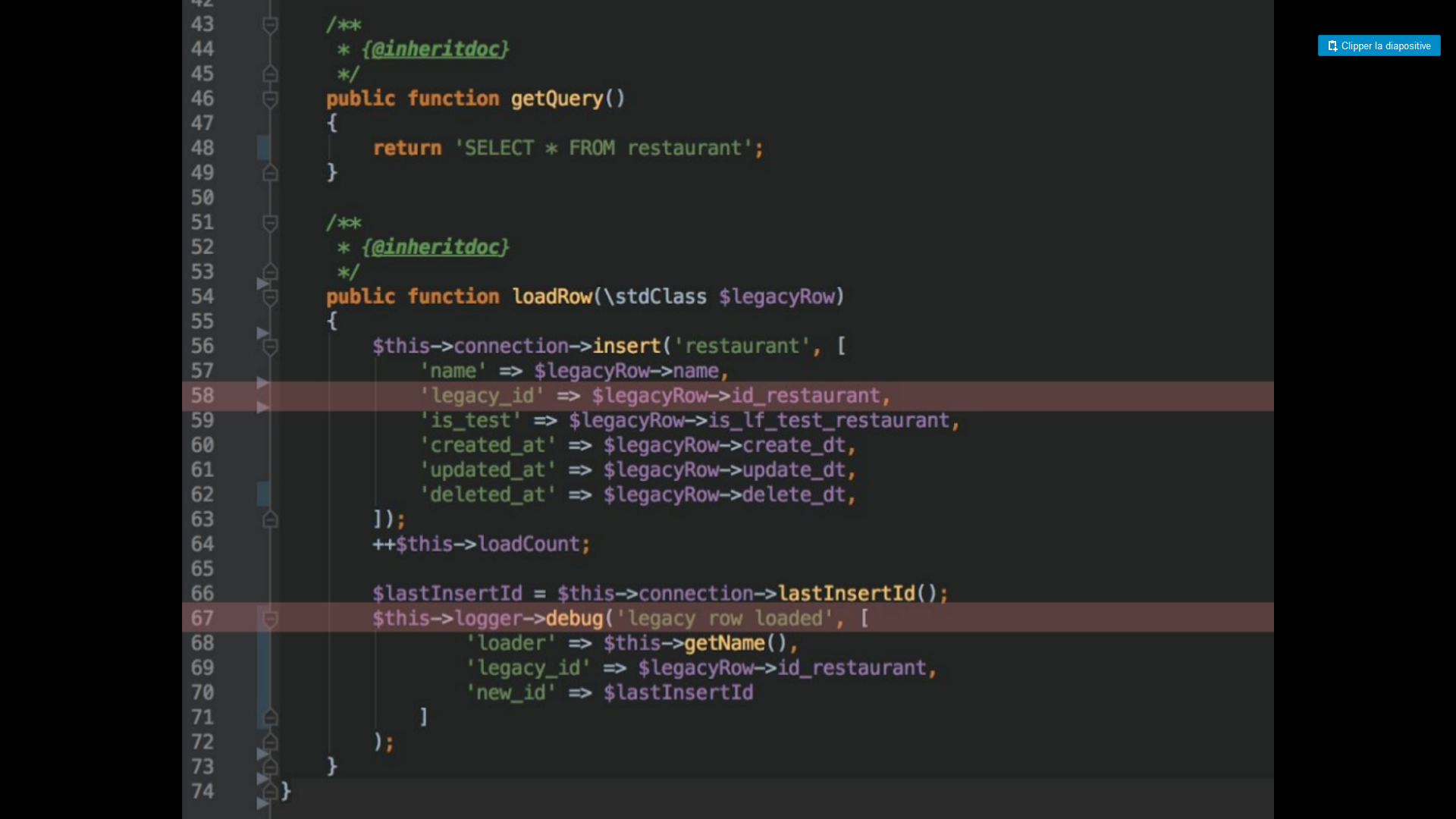
Transformers
Ils permettent de synchroniser les 2 bdd lors de l’écriture en base. Les données insérées ou modifiées sont ainsi présente dans les 2 bases.

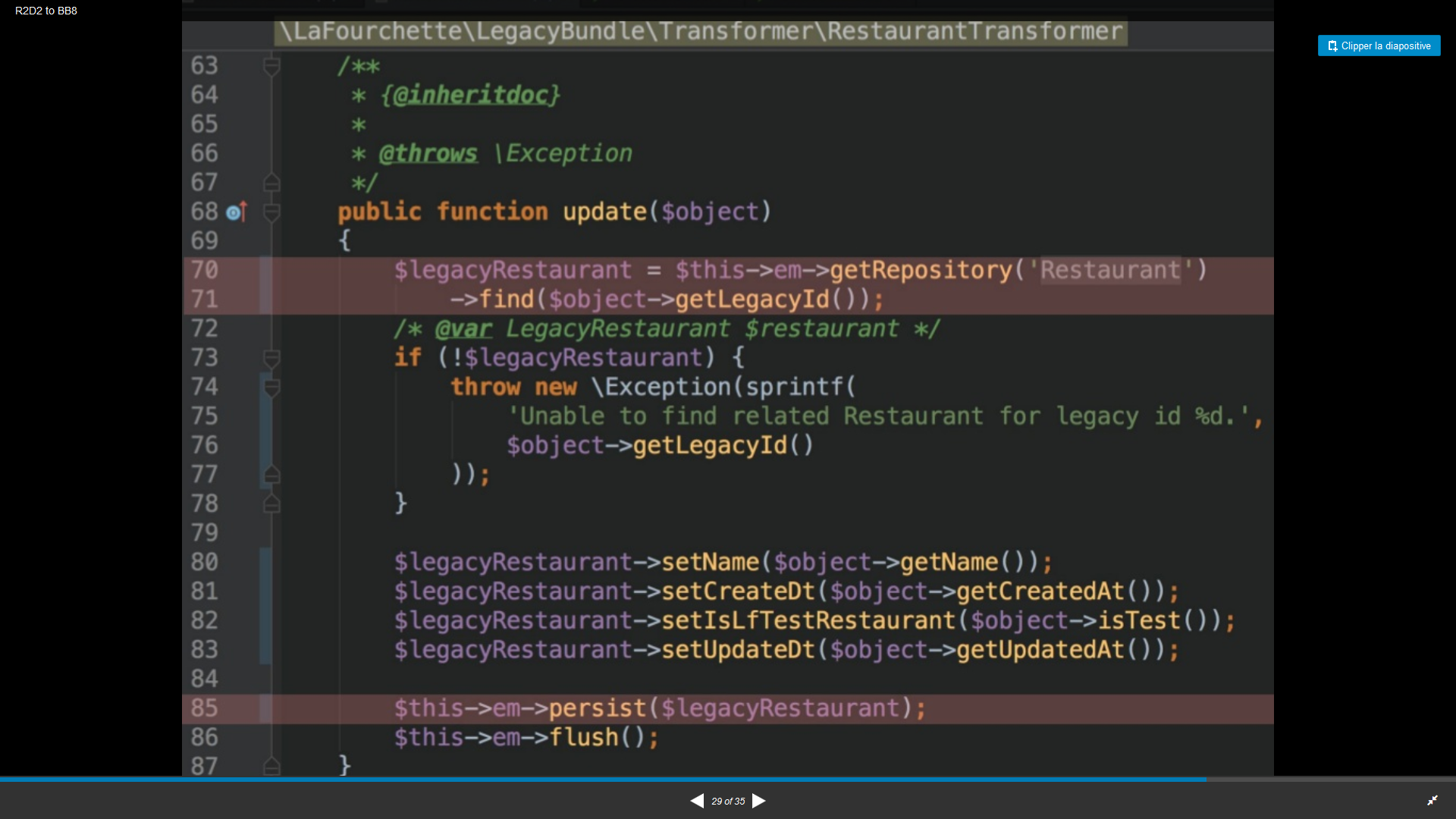
Double écriture
Certaines fonctionnalités ne sont pas encore présentes sur la nouvelle application, il faut donc les enregistrer sur les 2 bases. Ils utilisent donc des api sur la nouvelle appli qui écrivent en base via les Transformers (apiPlatform)
L’utilisation de LegacyBundle leur a permis de couvrir 75% des développements et de réduire le temps de dev à 1 an.
MemInfo : Memory Leaks
(par Benoit Jacquemont)
https://speakerdeck.com/bitone/hunting-down-memory-leaks-with-php-meminfo
L’extension PHP Meminfo permet d’étudier les pertes de mémoire liées aux objets utilisés dans les projets Symfony. Il liste les éléments mis en mémoire et détecter ainsi les les objets qui ne sont jamais libérés. Ce qui détériore significativement des performances : la mémoire bien sûr mais aussi les temps d’exécution.
Gestion de la mémoire liée à PHP
En PHP, les éléments comme les variables ou les classes sont stockés dans des éléments zbar. Ils sont en général supprimés après la fin de la session mais certains restent en mémoire et ne sont jamais effacés.
Au moment de la création de la classe, elle est mémorisée en zbar. Si on fait une référence de la classe dans un attribut, le compteur passe à 2. Après utilisation, la suppression de zbar de la classe référente libère la deuxième classe.
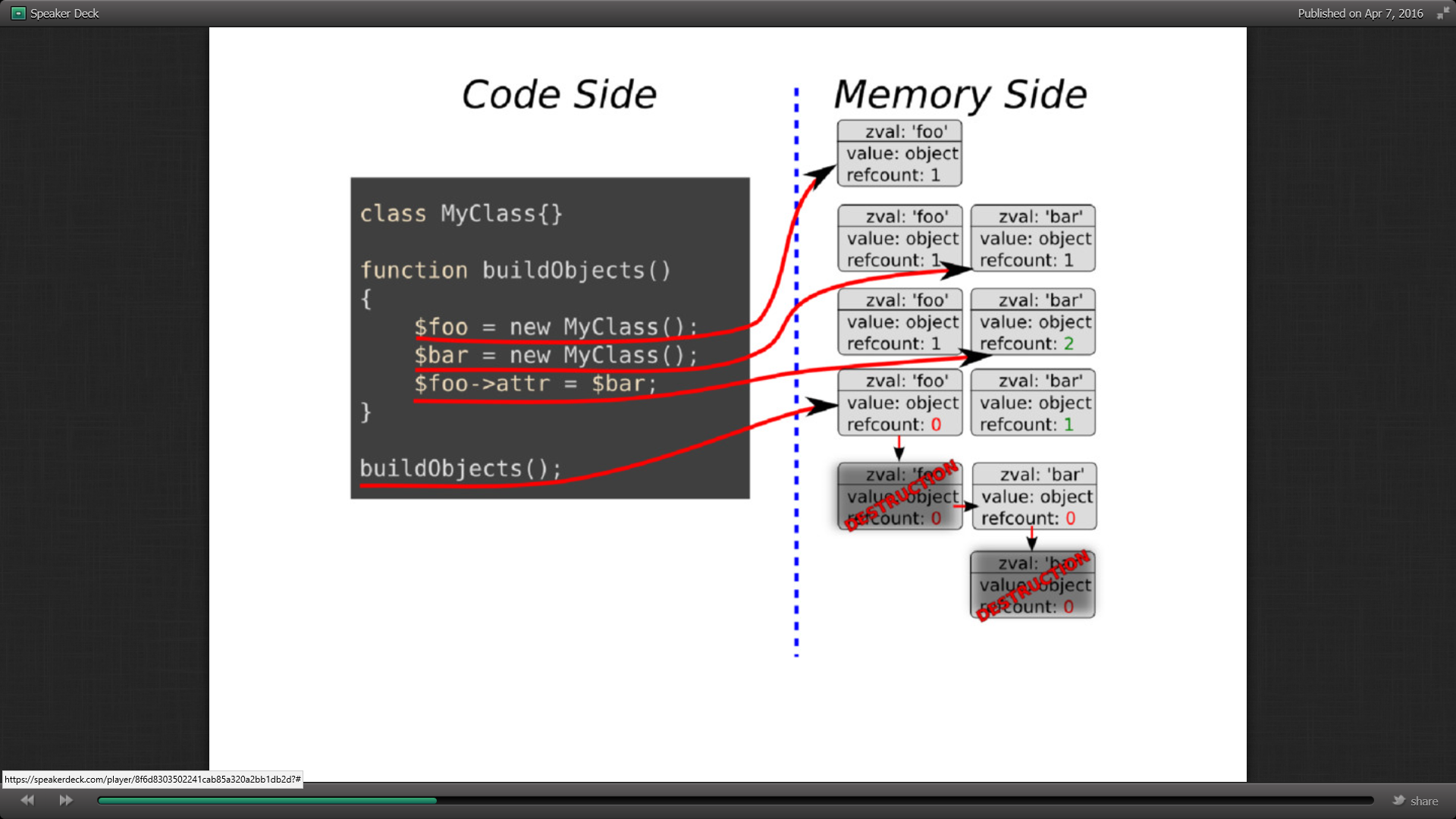
Mais si les deux classes se référencent, les compteurs des zbars des 2 classes est à 2 et lors de la décrémentation, aucune n’est supprimée. La session étant terminée, il n’y a plus de possibilités dans le programme pour libérer la mémoire. C’est un memory leak.
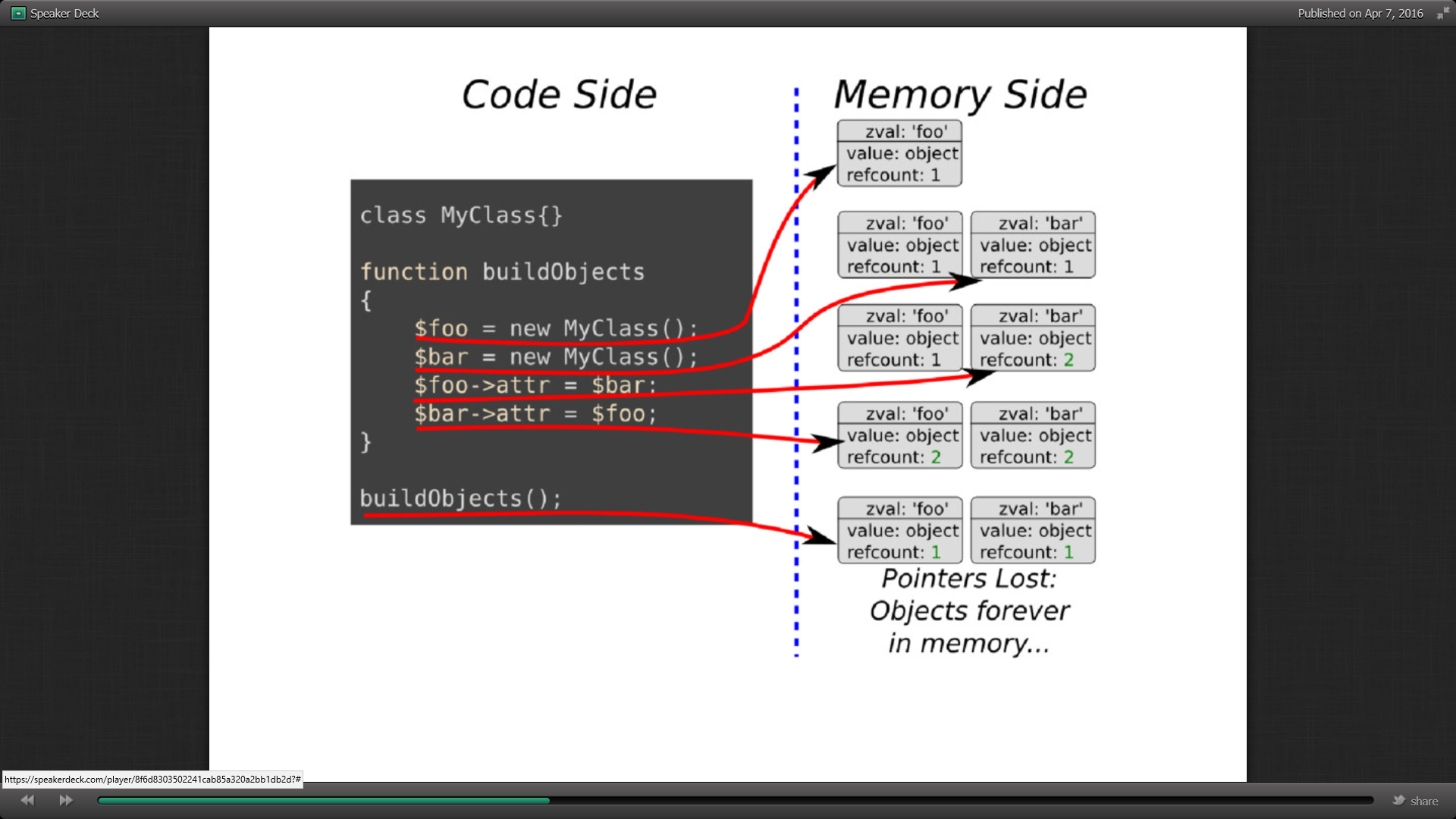
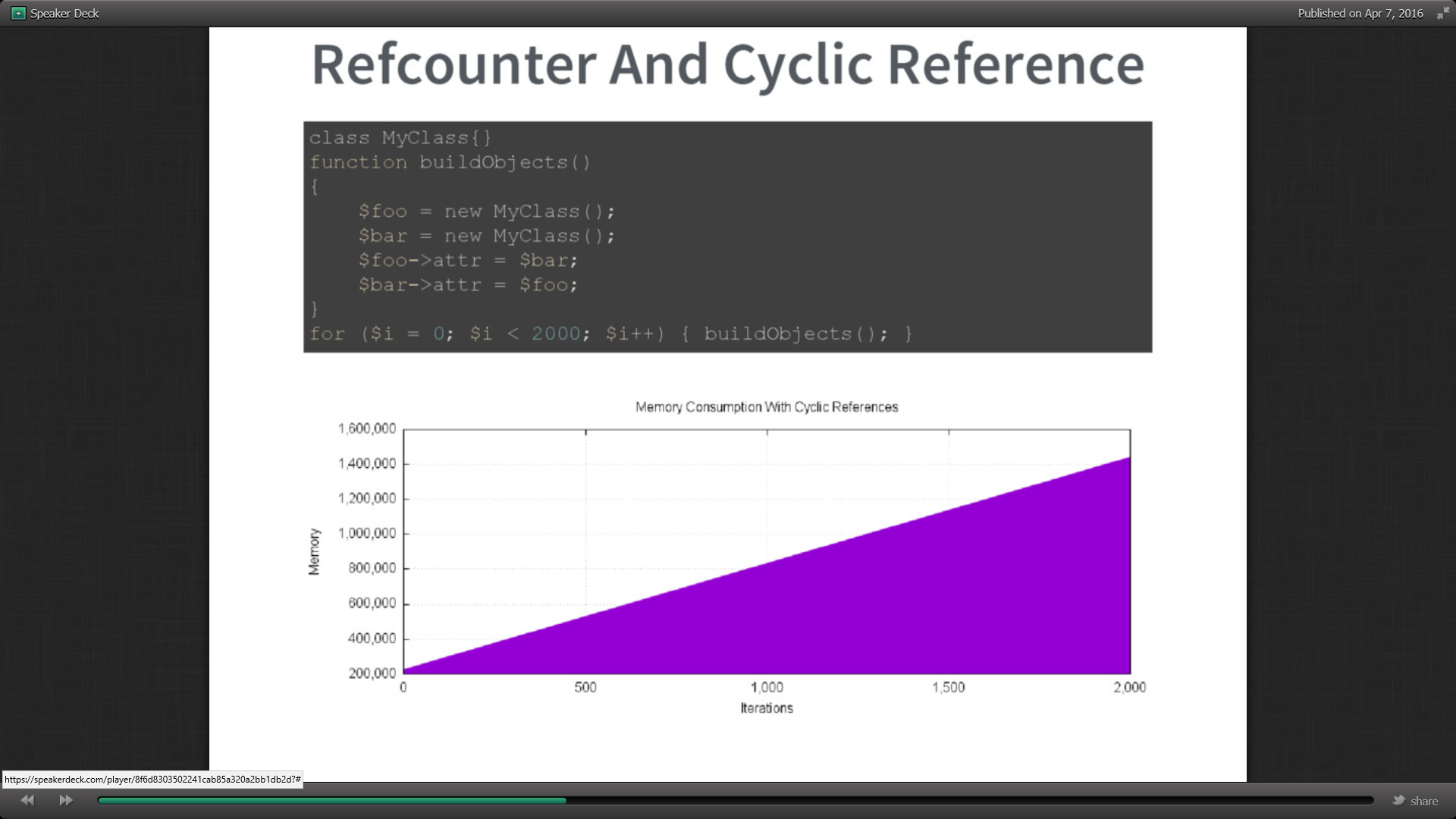
Dans Symfony, les exemples sont nombreux : les injections de dépendances des services et les associations dans doctrine, les références entre parents et enfants. La fonction garbage_collector() permet déjà d’identifier les items qui ne sont reliés à aucune variable et de les mettre en buffer. Mais si les références circulaires sont trop nombreuses et que le buffer est plein, le programme continue de le scanner. Ce qui détériore beaucoup les performances.
PHP Meminfo dans Symfony
PHP Meminfo identifie les memory leaks en analysant la mémoire utilisée. https://github.com/BitOne/php-meminfo
- meminfo_objects_summary($output) permet d’afficher le nombre d’instances d’une classe en mémoire dans un fichier ou une base de données déterminés par $output. Pour plus d’efficacité, le placer après un garbage_collector().
- meminfo_info_dump($output) : affiche le détail des variables en mémoire
- la commande bin/analyser query –f “name_class“ permet de voir les objets en mémoire (zbar)
Meminfo est facile à implémenter dans Symfony et est très utile pour détecter les erreurs de développement et les fuites mémoires qui coûtent chers en performances surtout dans les longs programmes en arrière fond.
Découpler ses applications en microservices
(par Fabien MEURILLON)
http://fabien.meurillon.org/sfLive2016/#1
Dans le cadre de la refonte du site Auchan E-Commerce, les équipes ont été amenées à découper le site en micro services via le pattern d’architecture orientée service SOA : https://fr.wikipedia.org/wiki/Architecture_orient%C3%A9e_services
Le concept permet de rendre les différentes fonctionnalités indépendantes et communiquant entre elles via des APIs. Chaque service correspond à un bundle chargeable via composer et concerne un domaine métier spécifique. Ils ont opté pour le pattern reactive Manifesto : http://www.reactivemanifesto.org/ constitué de :
- Responsive
- Resilient
- Elastic
- Message driven
Après étude, le composant ExchangeBundle, qui permet la communication entre applications via le filesystem ou la base de données (même par MOM : RabbitMQ) et de différer les traitements par des listeners déclenchés par un cron, ne répondait qu’à la notion de Message Driven et a donc été abandonné.
ApiBundle
En revanche, l’ApiBundle répondait aux autres critères sauf ce dernier. En effet, la communication entre les différents services (bundles) est assurée par des requêtes http dont la transformation en JSON ou en XML est faite par JMSSerializer. Des events sont déclenchés à chaque appel pour lancer les traitements en asynchrone. Les services sont ainsi indépendants et exemptés des notions métiers pour être réutilisé dans tous les projets.
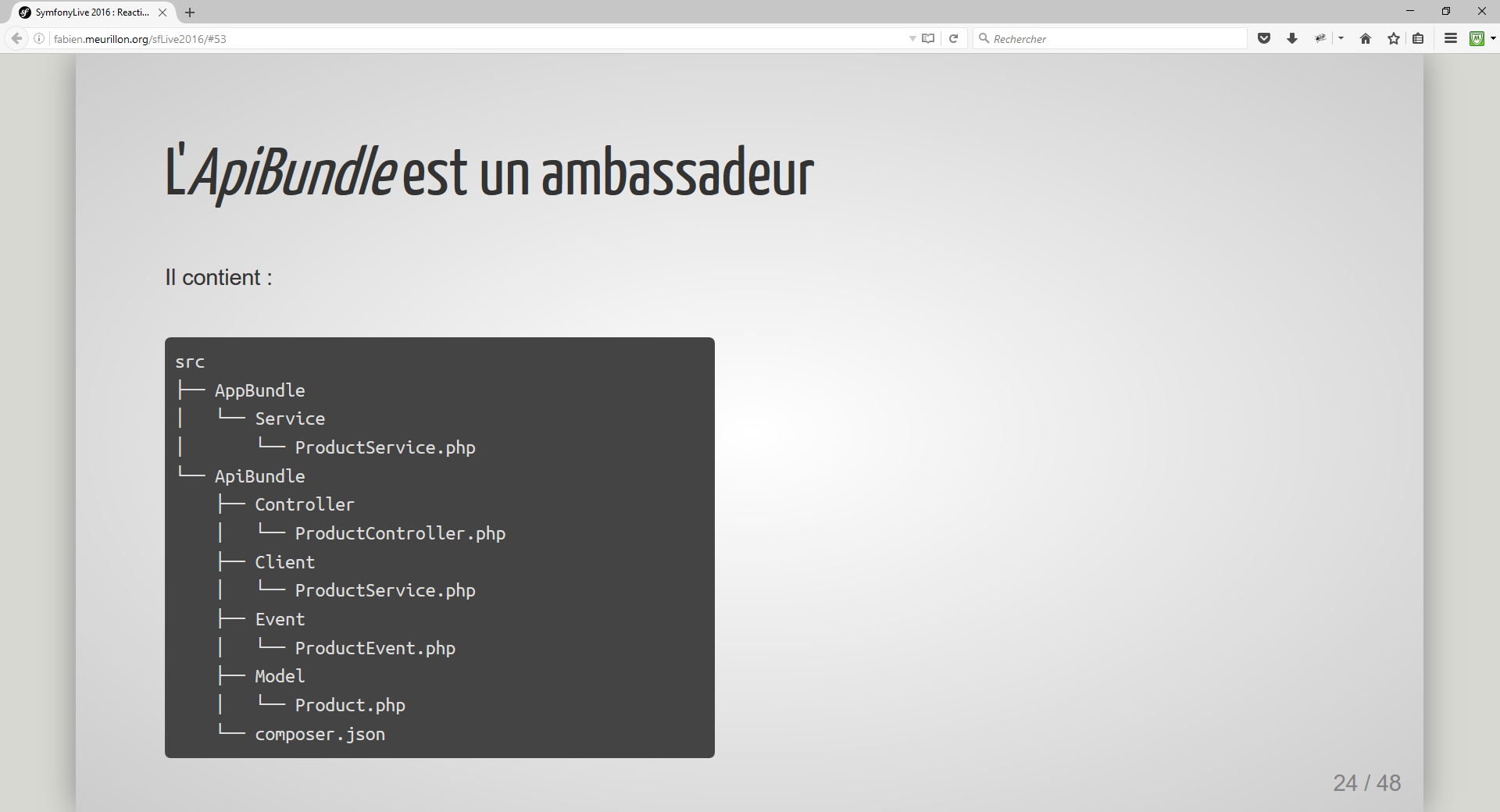
Dans lequel le client (Guzzle) fait le lien avec les applications métier de manière synchrone, les controleurs appelés poussent les modifications et les events déclenchent les actions en asynchrone.
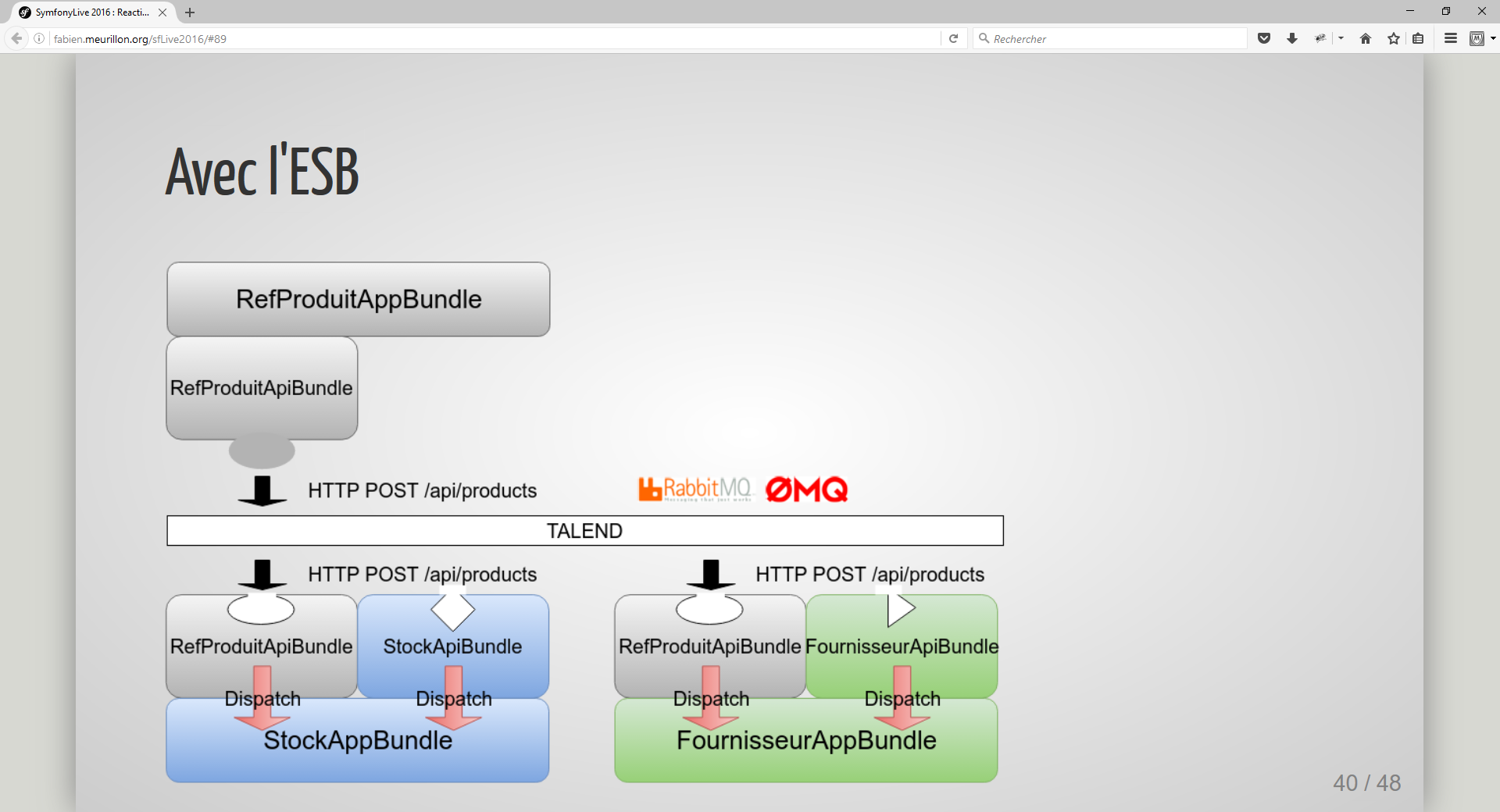
Talend ESB
Pour compléter, l’élément manquant, ils ont abandonnée PHP et ont opté pour une solution ESB (Entreprise Service Bus) : Talend ESB.
http://www.informationbuilders.fr/esb-bus-de-service-d-entreprise
Il gère le découpage applicatif et fait le lien entre l’ApiBundle et les services métiers. Ces derniers ne dépendent plus de l’infrastructure. Il permet :
- une garantie de delivery des messages
- un Message Oriented Middleware (RabbitMQ, ZeroMQ, …)
- un support complet de REST et des codes d’erreurs
- un Service Locator pour ne pas paramétrer en dur les adresses physiques des applications
- un routing avancé des messages
- le support des formats d’échanges des tiers
Le réveil du workflow
(par Grégoire Pineau)
https://speakerdeck.com/lyrixx/le-reveil-du-workflow
Il est courant dans les e-commerces ou éditoriaux de mettre en place des états et statut de données telles que la publication d’articles ou la mise en vente de produit. La notion de machine à état est donc importante à développer et le composant Workflow permet de l’appliquer dans Symfony.
Ce bundle sera disponible dans la version 3.2 de Symfony.
Réseau de Pétri
Après avoir listé les problématiques :
- Plusieurs acteurs sont susceptibles d’intervenir à différentes étapes du workflow : gestion de droits associés au workflow
- L’élément doit passer par toutes les étapes avant d’être validé : les étapes sont donc reliées les unes aux autres par des transitions
- Le chemin du workflow peut comporter des étapes parallèles : la relation entre état et transition est donc ManyToMany
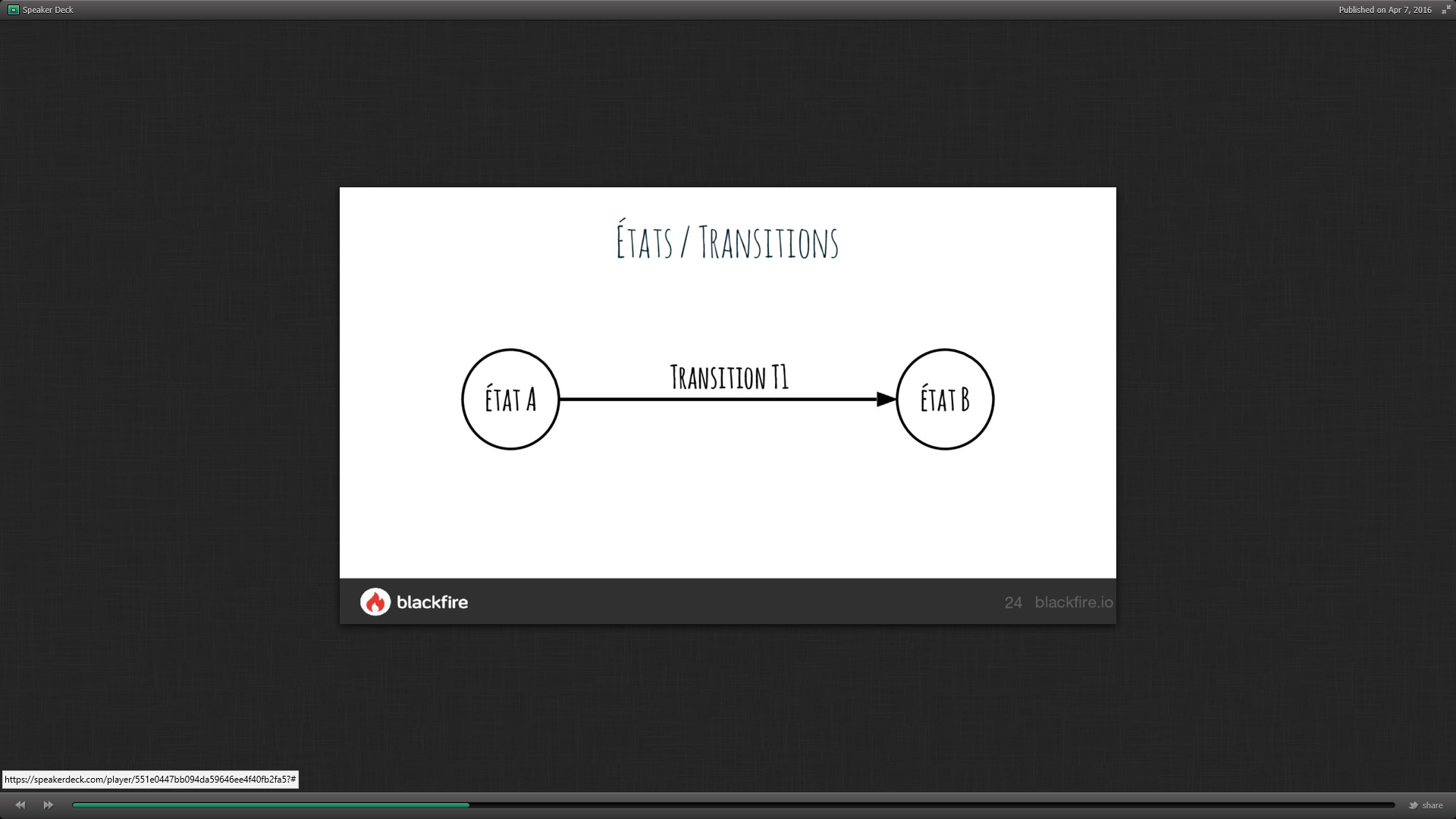
Il est basé sur le réseau de Pétri qui est un modèle mathématique représentant un workflow sous forme de Place/Transition dans des situations complexes : la transition devient un élément. https://fr.wikipedia.org/wiki/R%C3%A9seau_de_Petri
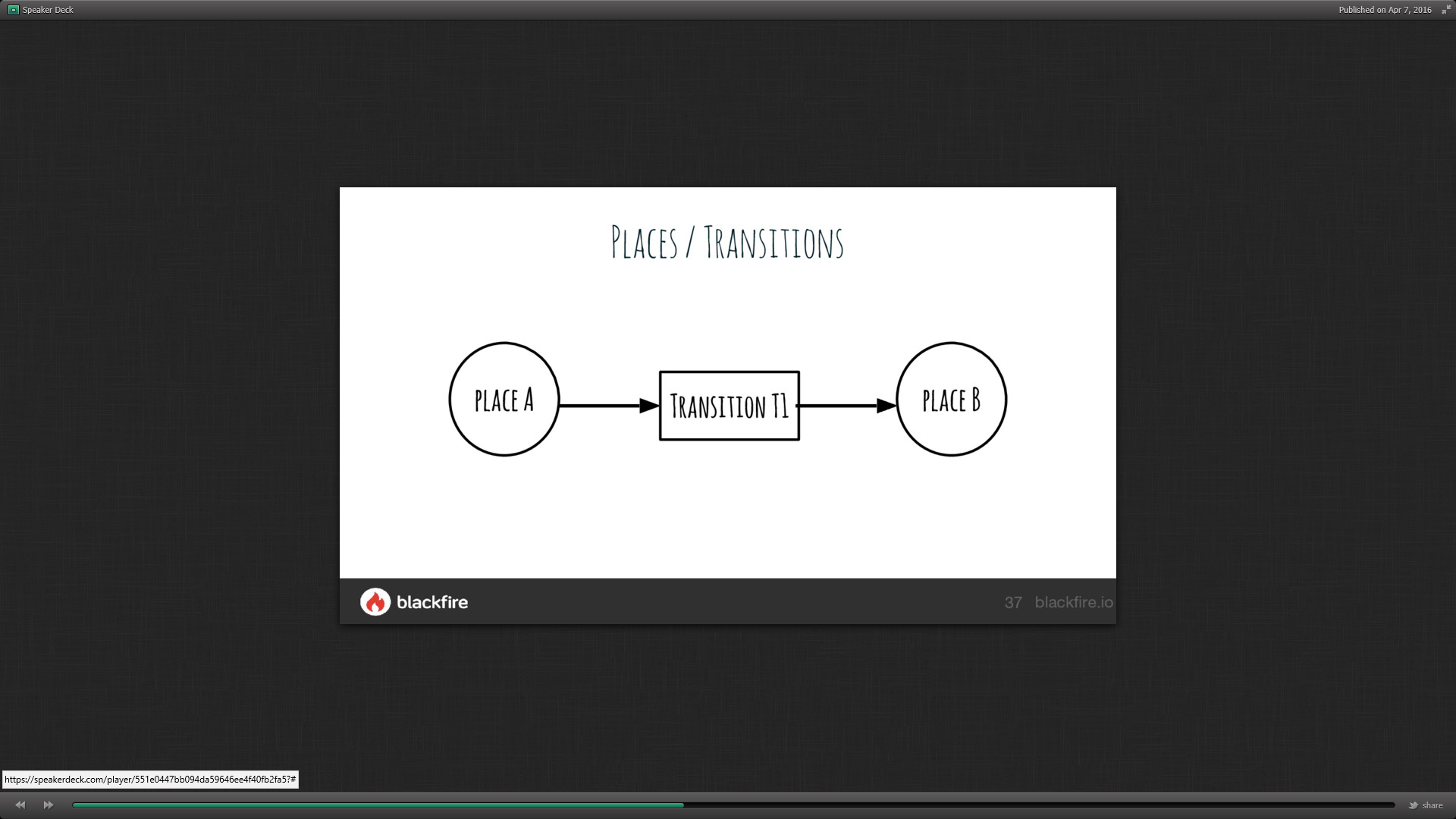
Bundle Workflow
Dans le bundle, la transition est représentée par la class Workflow qui propose entre autre 3 fonctions :
- can($subject, $transitionName) : vérifie que la transition est exécutable
- apply($subject, $transitionName) : active la transition
- getAvailableTransitions($subject) : liste les transitions disponibles
La classe Definition permet de faire le lien entre les places et les transitions et propose :
- addPlaces([liste des états]) : ajoute les états
- addTransition(new Transition([nom_transition], [liste_états], [liste_états])) : ajoute les transitions composé du nom de la transition, de la liste des étapes d’avant et la liste des états d’après.
La commande GraphvizDumper permet de modéliser une définition en schéma modélisé (dot) via la commande dump($definition).
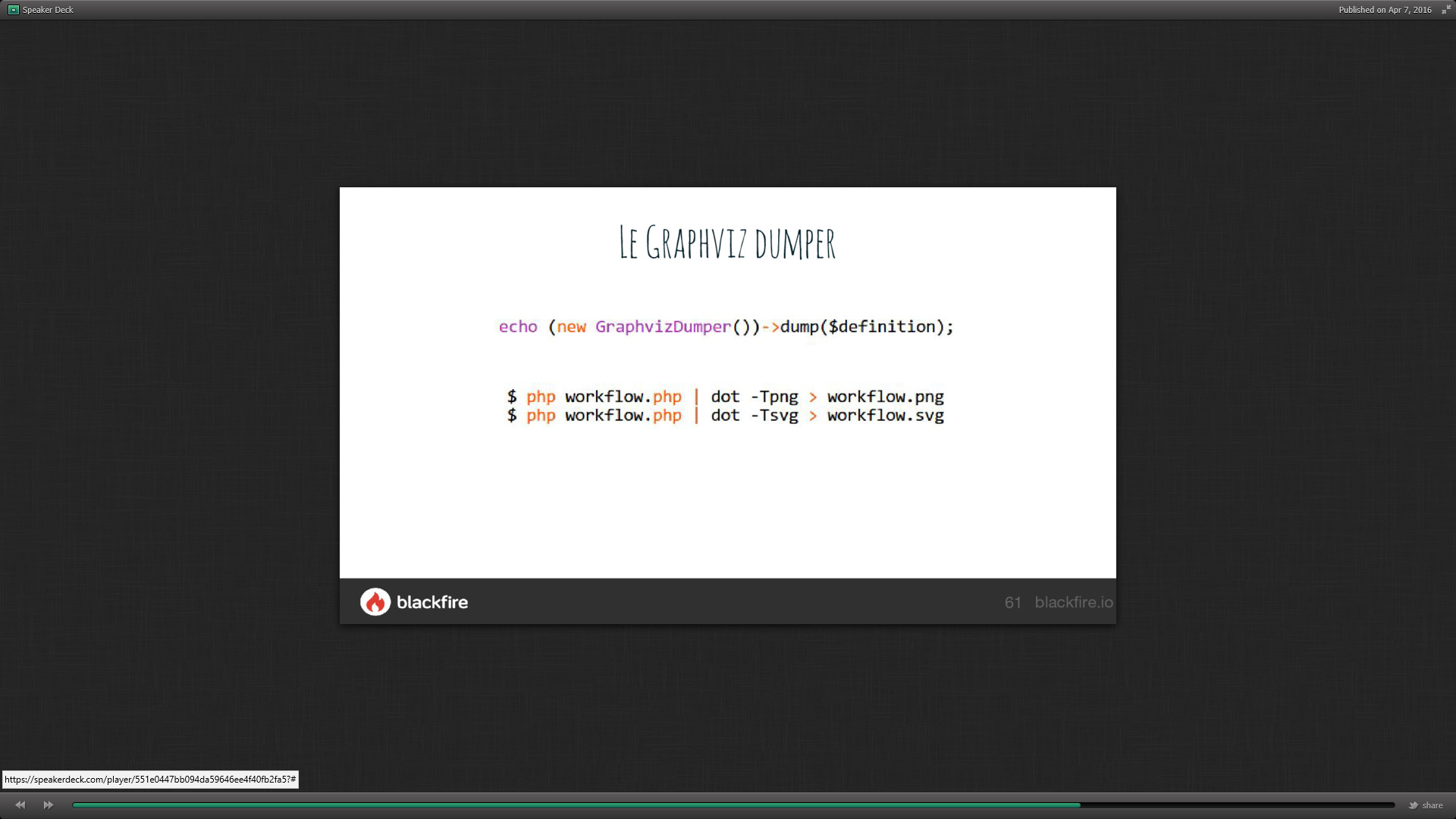
Le bundle utilise les Event Dispatcher pour déclencher les évènements lors de sortie d’état, passage dans une transition puis arrivée dans une place. Ils déclenchent notamment l’action GuardEvent qui permet de bloquer les transitions.
Pour configurer le schéma dans config.yml :
- définir les supports en pointant vers l’entité
- les états sont définis en yml dans l’attribut places
- les transitions en yml dans transitions en spécifiant le nom de la transition suivie des états antérieurs (from) te postérieurs (to)

La commande workflow :dump [nom_workflow] [place_origine] [place_destination] permet de générer le schéma graphique entre ces 2 états.
Les fonctions de Workflow sont disponibles dans les contrôleurs et les templates (twig) et associé au GuardListener permet de gérer la totalité du chemin.
Bla Bla Car : Elastic Search
(par Olivier DOLBEAU)
https://speakerdeck.com/odolbeau/elasticsearch-chez-blablacar
Le site Bla Bla Car utilise le moteur de recherche ElasticSearch pour traiter ses données. Elles sont ainsi disponibles immédiatement après insertion et les performances sont optimisées, aucune recherche dans les bases donc gain de performance (mémoire et rapidité).
Ce qui répond à leur nécessité de fournir les informations en temps réel et le calcul des statistiques car le volume de données et la fréquence de visite sont très importants : 250 Go de données, 2 millions d’indexation par mois, 5 millions de recherche par mois.
Le moteur de recherche propose des entités structurées en JSON dont tous les champs sont indexés, permettant de retourner rapidement des résultats complexes. Il propose également beaucoup de fonctionnalités pour personnaliser facilement l’indexage et les calculs.
API RESTful
Intégré dans Apache2 grâce à Lucene, il peut être utilisé via l’API RESTful. Cette api permet de gérer ElasticSearch par des requêtes curl :
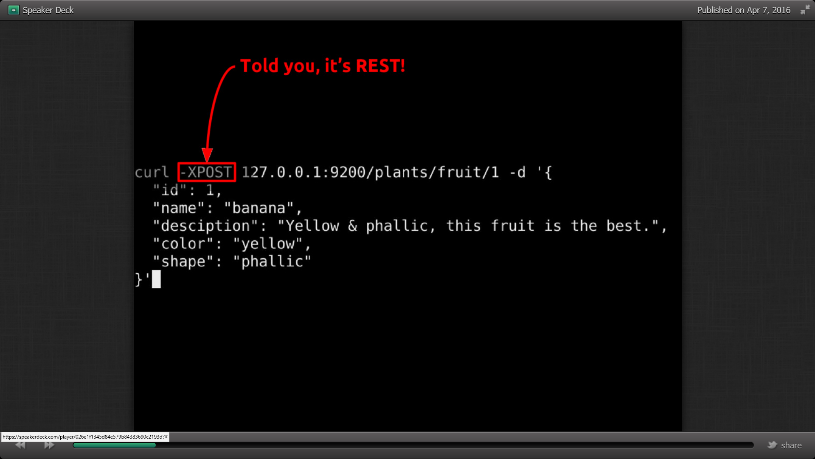
Pour insérer un élément :
On renseigne l’action (XPOST),
l’adresse du document dans Elactic
et le contenu de l’élément en JSON.
L’index est alors créé.
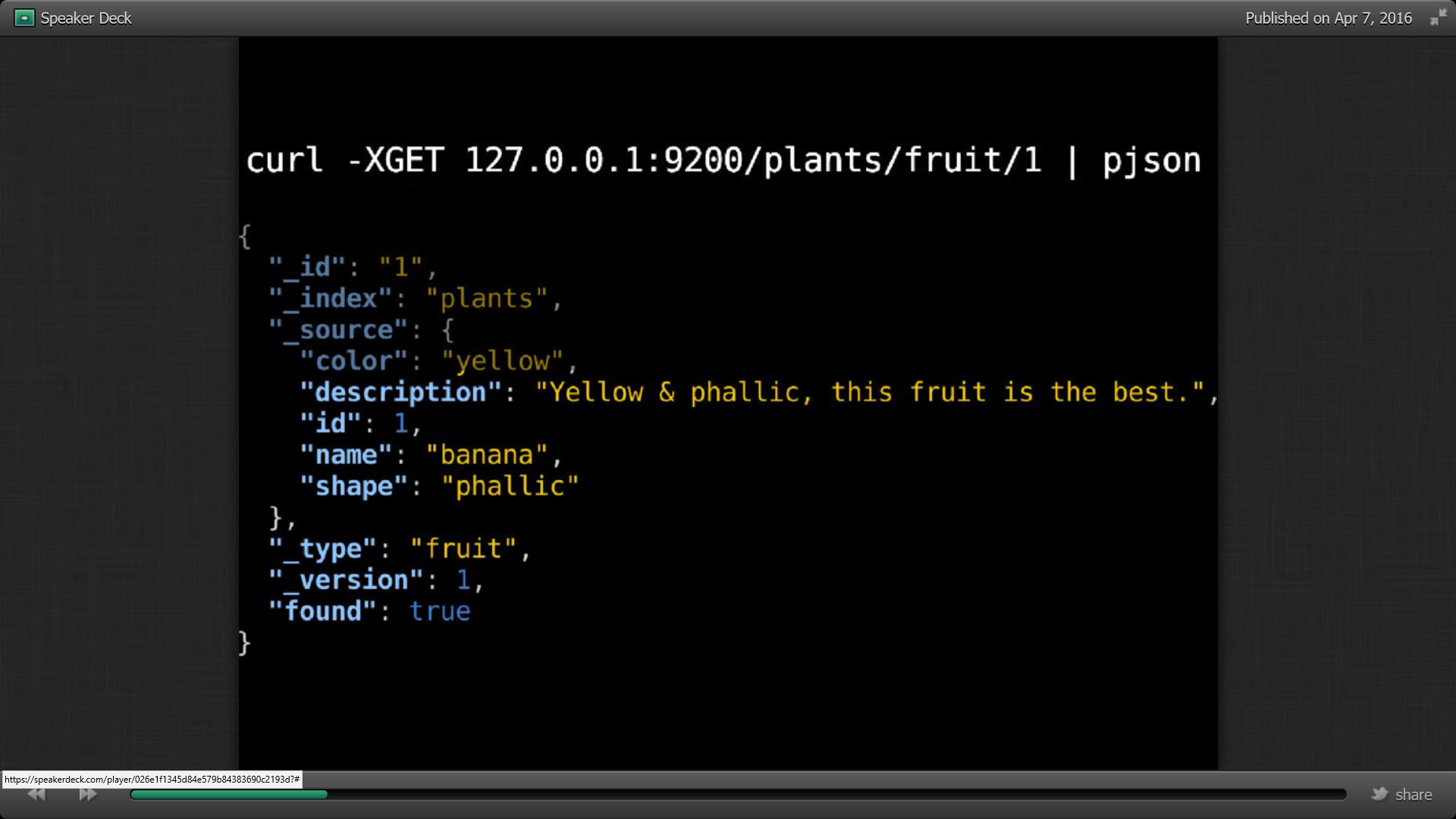
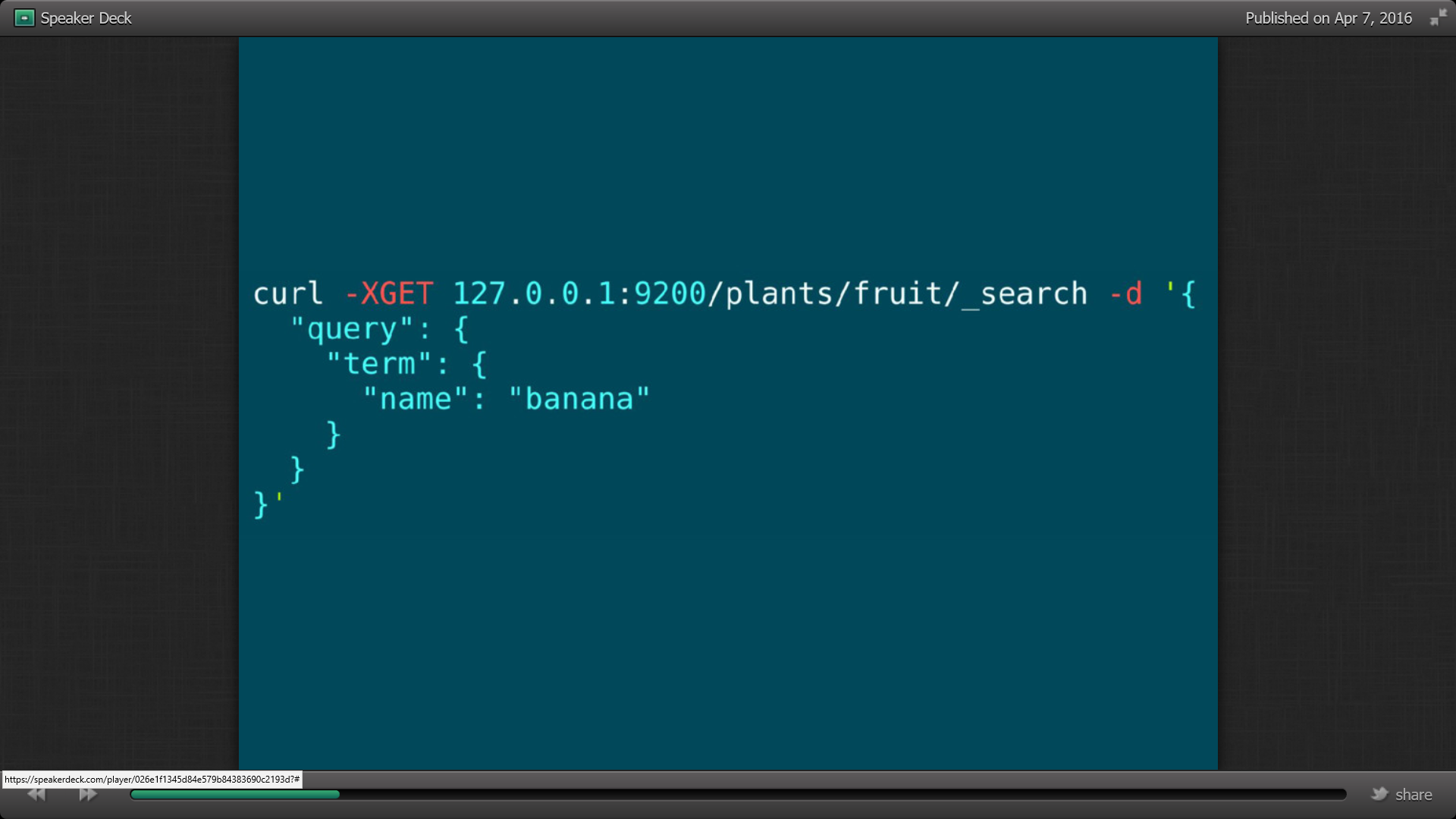
Pour récupérer l’élément, on utilise la commande curl –XGET suivi de pjson pour transformer l’objet en JSON :
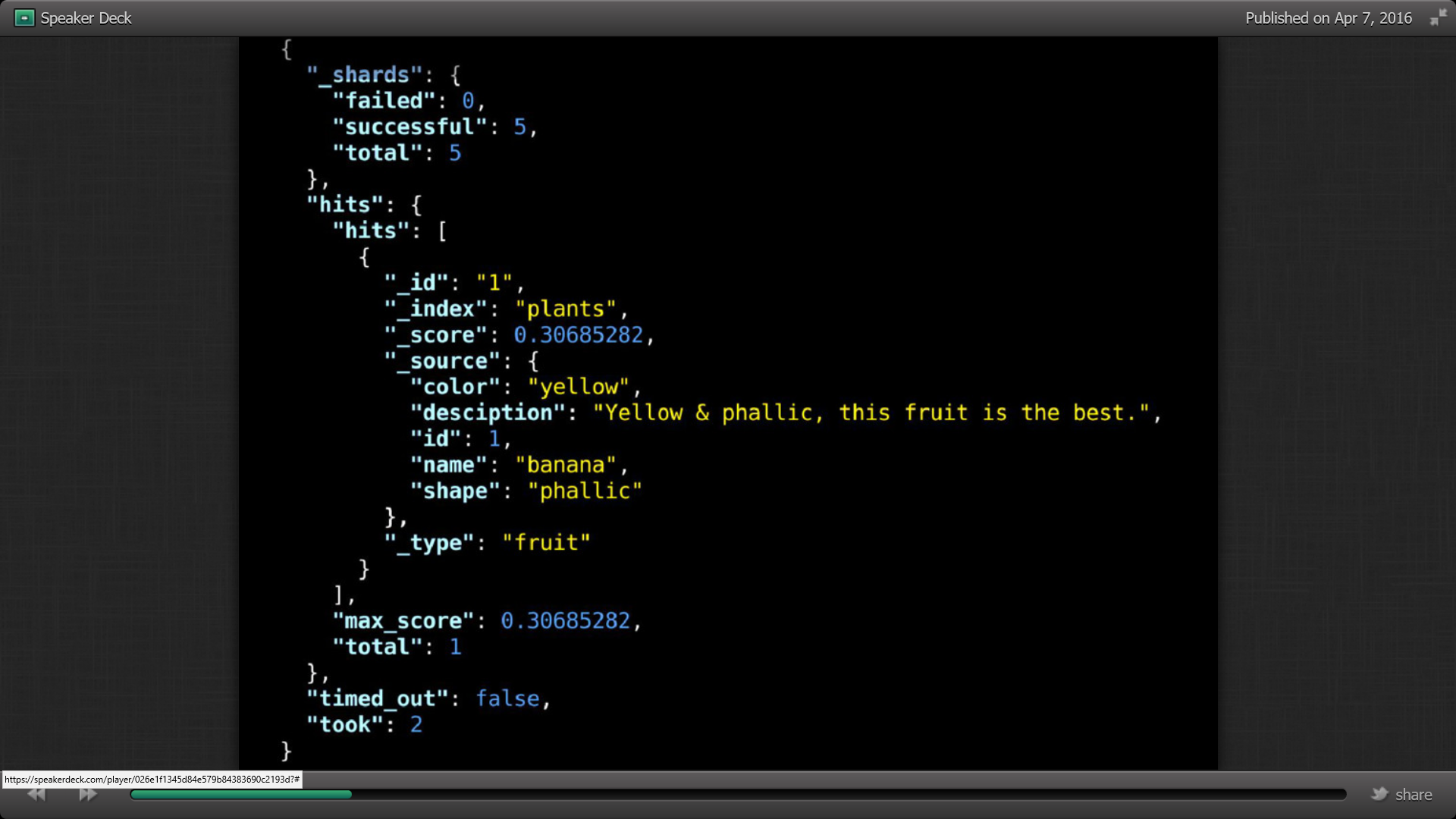
On peut faire des recherches avec la commande –XGET suivi de search –d et les paramètres de la recherche (query) en JSON. Il nous renvoie les éléments toujours en JSON dans hits.
Les filtres sont utilisés dans l’élément query : bool : filter, les aggrégations (facets) dans aggs.
On récupère ainsi les éléments filtrés et le nombre de ceux répondant au critère de la facet.
Le paramètre must permet de filtrer et est obligatoire mais match_all renvoie tout. Le typage des données permet de pousser les recherches :
- range pour les intervalles de données (prix, dates…)
- geo_distance pour les coordonnées et les distances (latitudes et longitudes)
Il est possible de calculer les facets séparément du filtrage grâce à post_filter et filtrer qu’une partie des facets.
Mise en application chez Bla Bla Car
Le projet Bla Bla Car est formé de 5 clusters :
- Magic Search pour la recherche filtrée
- Alarm creation pour la détection des thermes interdits dans les annonces
- IDK pour lire les logs et les stats
- Pour les alertes de voyage programmé et les routes favorites
- Les FAQ et les trajets les plus populaires
Elastica a été choisi pour faire le lien entre le moteur de recherche et l’appli
Scoring : utilisé pour privilégier dans les résultats d’une recherche sans les exclure de l’affichage en utilisant les filtres (ex : heure de départ, véhicule de luxe)
Performance au quotidien dans un environnement Symfony (Figaro)
(par Xavier Leune)
http://fr.slideshare.net/xavierleune/performance-au-quotidien-dans-un-environnement-symfony
Le groupe Figaro est le premier magazine français en ligne avec plus de 60 millions de vue. Les performances sont donc une priorité et les frameworks comme Symfony les dégradent mais permettent un développement plus rapide et standard. Ils ont donc opté pour son utilisation mais avec des limites.
Les requêtes ne doivent pas excéder par appel :
- 100 ms de chargement
- 8 mo de mémoire utilisée
- 10 requêtes SQL
Détecter les problèmes en dev coûtent moins cher qu’en production, en moyenne la correction d’un bug équivaut à 100€ en phase de développement, 1500€ en recette et 15000€ en production donc une phase de test importante.
Technologies utilisées : php, vanish, akamai, MariaDB, Sphinx, redis

Pour trouver le framework, ils ont utilisé la méthode de l’antonoir qui consiste à analyser plus précisément après sélection d’un étude moins poussée :

Constat : Symfony est le plus mature mais pas le plus rapide à cause surtout de l’ORM doctrine qui ralentit considérablement les requêtes, ils ont donc utilisé le PDO.
Pour simplifier l’écriture des requêtes dans Symfony, ils ont créé le bundle ting basé sur le pattern DataMapper qui permet d’exécuter les requêtes SQL : http://tech.ccmbg.com/ting
Optimiser le cache privé est bien sûr nécessaire mais il est souvent ignoré le cache public possible avec l’élément ESI qui permet de mettre le contenu d’une url en cache (utilisé dans le footer et header par exemple) et ainsi épargner les temps d’exécution de l’appel http.
Akamai pour la gestion de cache
Si la page est en cache, une requête demande au serveur si la page a été modifiée en comparant la date de dernière modification à l’heure de la requête. Il lui renvoie le code de réponse 304 qui lui indique que la page en cache peut être envoyée. Vanish ne permet pas de le gérer.
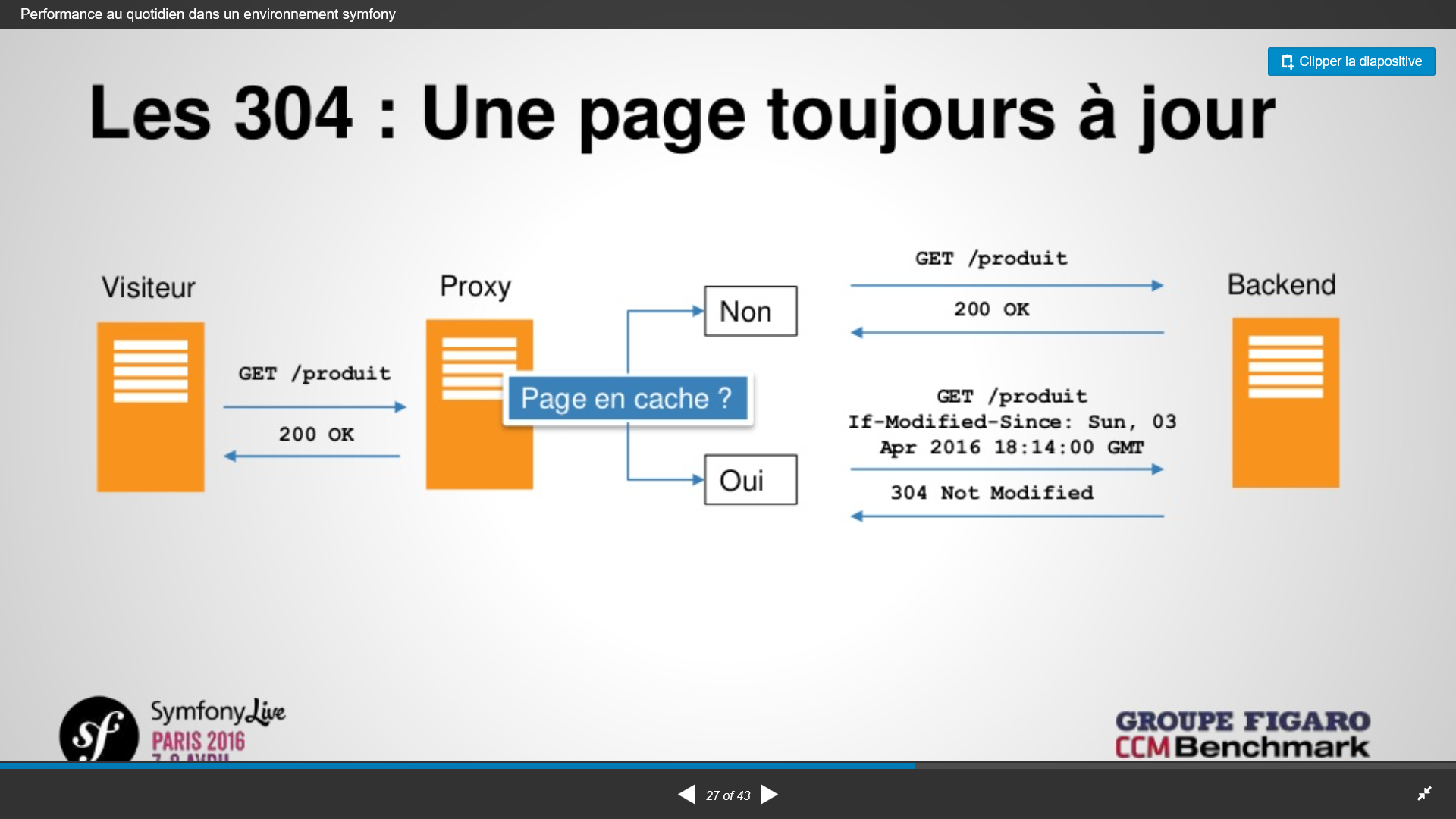
Attention au cache symfony (twig) car google référence les pages jamais visitées et le temps de réponse élevé défavorise le référencement. Donc utilisation de cache-warmup (dispo dans composer)
Pour le déploiement qui concerne plusieurs sites, ils utilisent RSync pour les tests en parallèle sur toutes les applications (test unitaire, behat, peer …) et Blackfire leur permet de tester les perfs avant la mise en prod et est automatisé dans l’intégration continue.

La confiance dans le travail d’équipe
(par Mathieu NEBRA)
https://speakerdeck.com/openclassrooms/pourquoi-se-faire-confiance
Contexte : évolution du travail d’équipe lors du développement du site du Zéro
Commencé seul, Mathieu NEBRA a monté progressivement une équipe de plus en plus importante. Il veut mettre en avant l’importance des interactions entre les membres de cette équipe.
Il a étudié les différentes stratégies d’entreprise qu’il a résumées en 2 opposés :
- Certaines partent du principe que ses employés sont flemmards et qu’ils ne pensent qu’à leur intérêt personnel (surtout financier). C’est pourquoi elles optent pour ne pas leur céder la prise de décisions importantes et leur imposer des tâches bien définies et chronométrées par leur hiérarchie. Ils doivent être remplaçables.
- D’autres prône la créativité de leurs salariés, qu’ils sont dignes de confiance mais faillibles. Elles leur laissent donc plus de liberté et de responsabilité pour arriver à des rapports moins hiérarchiques qui priment que le partage.
Après avoir essayé la méthode hiérarchique, il s’est rendu compte que les décisions étaient longues à être appliquées et que les cette situation générait des conflits au sein de son équipe, il a opté pour une méthode plus souple. Il pense alors que les préjugés d’une entreprise formalisent le comportement des salariés et met en place une stratégie axée sur 3 piliers :
Transparence de l’information :
Les réunions d’équipes sont publiques et décontractées, les bureaux sont transparents pour que tous les acteurs de l’entreprise puissent être en contact visuel. Les statistiques et les informations de l’entreprise sont accessibles à tous et présentées lors d’une réunion mensuelle dans laquelle chacun présente son travail devant tout le monde. L’outil de discussion slack est utilisé pour favoriser les échanges rapides. Organisation de déjeuner de groupe et d’évènements sportifs et culturels leur permet de rester soudés : une bonne cohésion d’équipe.
Traitement des tensions
Pour éviter les malentendus, premier facteur de conflit car se transforment rapidement en rancœur, des réunions sont organisées régulièrement dans lesquelles chaque salarié peut donner son ressenti sur 3 autres personnes (patron compris) devant tout le monde. Matthieu fait part de débuts difficile parce que les malentendus étaient nombreux et difficiles à entendre mais au fur et à mesure, les réunions sont devenues détendues. Des médiateurs tiers peuvent aider à résoudre les conflits persistants.
Diffusion des responsabilités
Il faut définir une mission commune où chacun a le pouvoir de décision, partage sur les problèmes et les solutions lors de rétro sprint et feedbacks. Mathieu conseille à ses équipes d’être humble et de ne pas hésiter à demander l’avis aux autres. Cela permet de valoriser et responsabiliser tout le monde.
PSR6 : cache
(par Nicolas Grekas)
PHP-FIG (PHP Framework Interop Group) donne les bonnes pratiques de développement, il édite les standards sur lesquelles on peut se baser. Il comprend parmi d’autre : (http://www.php-fig.org/)
PSR 6 : développement de librairies de gestion de cache interface destinées à rendre les développements qui les utilisent non personnalisés.
PSR 7 : développement d’interfaces prônant les standards de requête http. Les éditeurs de doctrine/cache qui sont les leaders des services de cache) ont eu trop de problèmes avec ses nouvelles normes donc les équipes de Symfony développe une suite :
Le composant Symfony Cache
Il implémente des objets de cache : CacheItem
- isHit() permet de savoir si l’objet est en cache
- expiresAfter() : détermine la période de validité
- save() : sauvegarde l’objet en cache
- saveDeferred() : ajoute l’objet en différé
- commit()
L’interface CacheItemPoolInterface permet de manipuler le cache dans une seule classe. Il respecte les nouvelles normes de PSR6.
- getItem($key) : récupère l’objet de clé $key
- hasItem($key) : vérifie la présence de l’objet de clé $key
- deleteItems(Array $keys) : supprime les objets
- save($item) : enregistre l’item en cache
- saveDeferred() : enregistre en différé
- generateItems($items) : crée les objets en cache
- clear() => vide le cache
Sécurité web: pirater pour mieux protéger
(par Alain TIEMBLO)
https://github.com/ninsuo/slides
La sécurité est très importante dans les sites internet et permet de se protéger contre les attaques extérieures. Mais pour mieux appréhender ce domaine et trouver des solutions, il faut se mettre dans la peau d’un hacker.
Authentification
Les mots de passe ne doivent pas être stockés en clair en base de données mais hashés. Si la base de données est récupérée, les passwords ne pourront pas être déchiffrés. Il est même conseillé d’utiliser de les concaténer avec un code unique par user (salt). En effet, beaucoup de personnes utilisent souvent les mêmes mots de passe (azerty, 1234…) ce qui peut amener un hacker à trouver le cryptage du hash. Avec un salt, les hashs sont tous différents et deux mêmes pass ne seront pas conservés sous le même pass crypté. Utiliser la fonction bcrypt. Pour savoir si son email a été piraté : https://haveibeenpwned.com.
Un procédé de hacking (BruteForce) consiste à envoyer des demandes d’annulation du mot de passe sur une liste d’email pour savoir si un compte les utilisent comme login. Pour éviter cela, ne pas permettre le changement du password plus d’ »une fois par jour et ne pas envoyer de réponse d’erreur. Lors d’échec de connexion, ne pas préciser la nature de l’erreur (bad login ou bad password) et limiter les tests de connexion (pause d’1 minute après 3 tentatives).
Injection de code
Il est possible via les debuggers comme firebug de modifier les valeurs des champs cachés ou autre qui trompent une fois envoyé au formulaire (anecdote sur les places offertes de la sncf). Il ne faut donc pas utiliser de champs hidden pour stocker des informations calculables sur le serveur ou toujours dupliquer d’un contrôle en backoffice.
Il est également possible d’injecter du code indésirable dans les champs de formulaire. La fonction htmlspecialchars() permet d’échapper le code html et ainsi de ne pas l’interprété. Twig l’utilise par défaut mais pousse le contrôle avec le modifier e : suivi de html, html_attr, js ou css, il permet d’éviter les injections de code.
Pour se protéger des abus des camps éditeur enrichi (RTE ou WYSIWYG), il faut utiliser le composant HTMLPuriferBundle dans Symfony et le modifier purify à la place de raw dans twig. http://htmlpurifier.org/
Clickjacking
C’est un procédé qui consiste à surcharger des zones d’un site avec des liens commerciaux ou malveillants : ces liens sont bien sûr transparents et l’utilisateur ne s’en rend pas compte. Cela devient vraiment problématique dans les formulaires d’envoi de données personnelles telles que bancaires. Pour les contrer utiliser les headers X-Frame-Options
(X-Frame-Options: SAMEORIGIN ou X-Frame-Options: DENY) pour les rendre visible.
SMS Verification Hacks
Il est possible de compléter un changement de profil par un envoi SMS pour éviter les modifications non voulues. Pour renforcer la sécurité, il est préconisé de doubler les vérifications :
- en cas de changement d’email, envoyer une confirmation par SMS
- en cas de changement de numéro de téléphone, envoyer une confirmation, par mail et sur l’ancien téléphone (en option)
- vérifier la validité du numéro de tel via nexmo (yopmail existe aussi pour les téléphones)
- limiter la saisie en cas de contrôle via le code pin
- limiter le renvoi d’informations par SMS car payant en cas de click intempestifs en mettant une temporisation et une désactivation après sollicitation
Cross-Site Request Forgery
Pour se protéger des attaques CSRF, ajouter des tokens dans les formulaires qui permet de vérifier que son retour est bien celui attendu par le serveur. Utilisé par défaut dans les forms de Symfony.
Website Crawling
Utilisé par les hackers pour récupérer les données ou étudier les informations business, il est possible de s’en prévenir en limitant les sessions par IP et les visites par session pendant un certain temps. Ces informations sont disponibles dans $_SERVER.
Pour éviter les abus de cookie, renseigner des périodes de validité (expires) et utiliser des captcha.
Aller plus loin avec Doctrine2
(par André Tapia et Amine Mokeddem)
Vocabulaire DQL
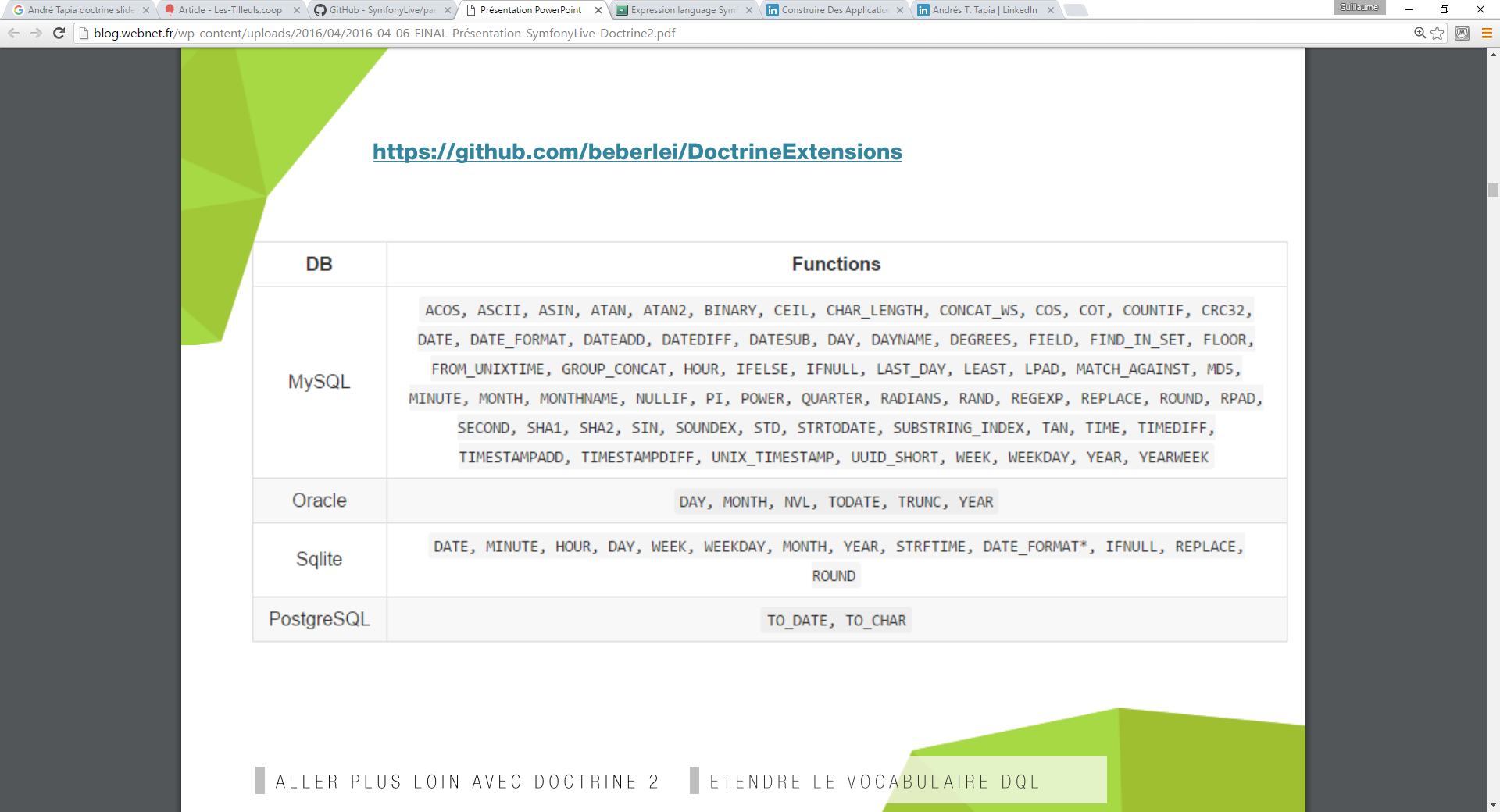
Doctrine2 permet d’étendre le vocabulaire DQL qui est utilisable dans symfony via la méthode addSelect([requête DQL]) du queryBuilder.
Beaucoup de fonctions SQL sont disponibles : http://github.com/beberlei/DoctrineExtensions
Les listeners
Doctrine2 propose plusieurs listeners de type LifeCycleCallbacks (PrePersist, PostPersist, preUpdate, postUpdate, preRemove, postRemove et postLoad) et les autres (loadClassMetadata et preFlush, onFlush, postFlush) qui permettent de déclencher des actions lors des différentes étapes de modification d’une entité.
Mais ces derniers sont restreints à l’entité dans laquelle ils sont déclarés (en annotation @ORM\HasLifecycleCallbacks dans l’entité et @ORM\PrePersist dans la fonction) et doivent être répétés dans toutes les entités qui suivent le même comportement. Les subscribers peuvent alors être utiles.
Les subscribers
Ce sont des services qui sont déclenchés par les évènements ci-dessus pour toutes les entités. Ils nous permettent donc de centraliser les listeners des entités qui implémentent la même interface. Les entités des bundles tiers sont ainsi accessibles sans avoir besoin de les surcharger et tous les autres services sont aussi accessibles.
La méthode onFlush() permet d’accéder à toutes les entités modifiées et ajoutées dans la même transaction via les méthodes getScheduleEntityInsertions, getScheduleEntityUpdates, getScheduleEntityDeletions mais les méthodes getScheduleCollectionsDeletions() et getScheduleCollectionsUpdate() ont été ajoutées pour gérer les collections. La fonction computeChangeSets() permet de valider les changements et de lancer les autres events des entités impactées.
Améliorer les performances
L’entityManager propose des fonctions utiles pour rendre l’ORM plus performant en vidant la mémoire et en utilisant les fonctions disponibles pour modification :
- setSQLLogger(null) : désactive les logs SQL
- detach($entity) : libère la mémoire de l’instance
- iterate() : boucle sur les résultats d’un queryBuilder et vide la mémoire après utilisation
- getConnection()->update($class, Array $datas, Arry $query) : permet d’exécuter la requête de modification décrite dans $datas pour les entités de classe $class et filtrées par $query. Améliore les performances de manière significative.
- createQueryBuilder()->update($class, $alias)->set([req en DQL])->getQuery()->execute() : modification d’une entité.
Les Hydrators
Les hydrators permettent de récupérer les résultats des query sous différentes formes.
- Query ::HYDRATE_OBJECT : retourne des objets entité
- Query ::HYDRATE_ARRAY : retourne un tableau
- Query ::HYDRATE_ SCALAR : retourne les identifiants
- Query ::HYDRATE_SINGLE_SCALAR : retourne le premier identifiant
Mais ils sont personnalisables en implémentant AbstractHydrator et déclaré dans config.yml dans hydrators.
Les Filters
Les filtres, implémentent SQLFilter et déclaré dans config.yml dans filters, permettent de récupérer les entités qui répondent aux critères définis dans le filtre en SQL (aussi utilisable dans la fonction where() du queryBuilder).
Ils sont très utiles dans les listeners pour identifier certaines données ou pour ne renvoyer que les résultats autorisés pour un utilisateur par exemple.
De plus ils peuvent être désactiver via les fonctions disable() et enable() : très utilies pour gérer les suppressions logiques.
Refondre un moteur de règles avec l’expression language de symfony2
(par Hussein Abbas)
https://speakerdeck.com/husseinab/expression-language-symfony-live
Après de longues recherches dans différents langages, notamment un long test de ruler mais décevant, Sell Secure, une startup de lutte contre des fraudes CB, a opté pour Expression Language en Javascript.
Implémentable dans symfony : symfony/expression_language,
Il est basé sur la syntaxe de twig et permet de compiler les expressions en PHP ce qui est plus facile pour le métier qui définit les règles et ne connait souvent pas l’informatique.
Les regexp sont également utilisables et les retours sont des booléens.
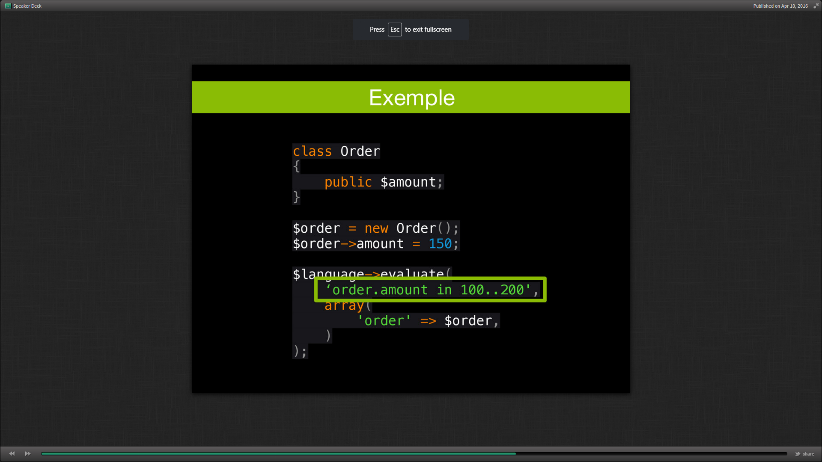
Ici, la fonction evaluate() permet de savoir si le montant de la commande est compris entre 100 et 200.
Ils ont pu ainsi simplifier l’écriture des fonctions métier qui étaient à la base en JSON (très compliqué à écrire) et réduire leur code source (plus de 450 à 15 lignes) et les performances ont été multipliées par deux. Il reste tout de même encore des optimisations de prévue :
- Optimisation de perfs
- Augmenter les possibilités d’expressions
- Créer une interface de saisie des règles
- Créer des validators de règles
- Enregistrer les règles en base de données
Sécurité et http
(par Romain Neutron)
https://speakerdeck.com/romain/securite-and-http-at-symfony-live-paris-2016
La sécurité dans les applications est devenue primordiale. Nous utilisons déjà des outils applicatifs (csrf token, auto escaping Twig, hashage de données …) mais plusieurs possibilités sont offertes par les navigateurs. La commande curl –I [url] permet de voir les paramètres http utilisé par le site ciblé.
Différentes solutions
Il est possible de les configurer via des bundles de Symfony :
- X-XSS-Protection : bloque les injections XSS
- X-content-type-options : nosnif _ vérifie le type déclaré d’un contenu via le MIME.
- Content Security Policy : default ‘self’ ; script-src ‘self’ [url] ; style-src ‘self’ [url] _ permet de préciser la source des fichiers chargé dans le site : images (img-src), css (font-src), ‘self’ représente le serveur du programme et [url] les urls supplémentaires utilisées. Les url peuvent être hashé pour plus de sécurité. La balise form-action permet de protéger les formulaires. Contre les attaques XSS.
- X-Frame-Option : SAMEORIGIN _ prévient le click intempestif
- Strict-Transport-Security :max-age=expireTime [ ; includeSubDomains] [ : preload] _ renforce la sécurité HTTPS en vérifiant la provenance du certificat. L’option includeSubDomains étend l’option aux sous-domaines et preload lance la vérification avant le chargement.
Mise en application dans Symfony :
Composer require nelmio/security-bundle permet de charger le plugin de sécurité.
Les CSP peuvent être configuré dans config.yml :

Il peut être utilisé par twig via {% cspscrpit %} pour protéger les scripts utilisés et {% cspstyle %} pour le CSS.
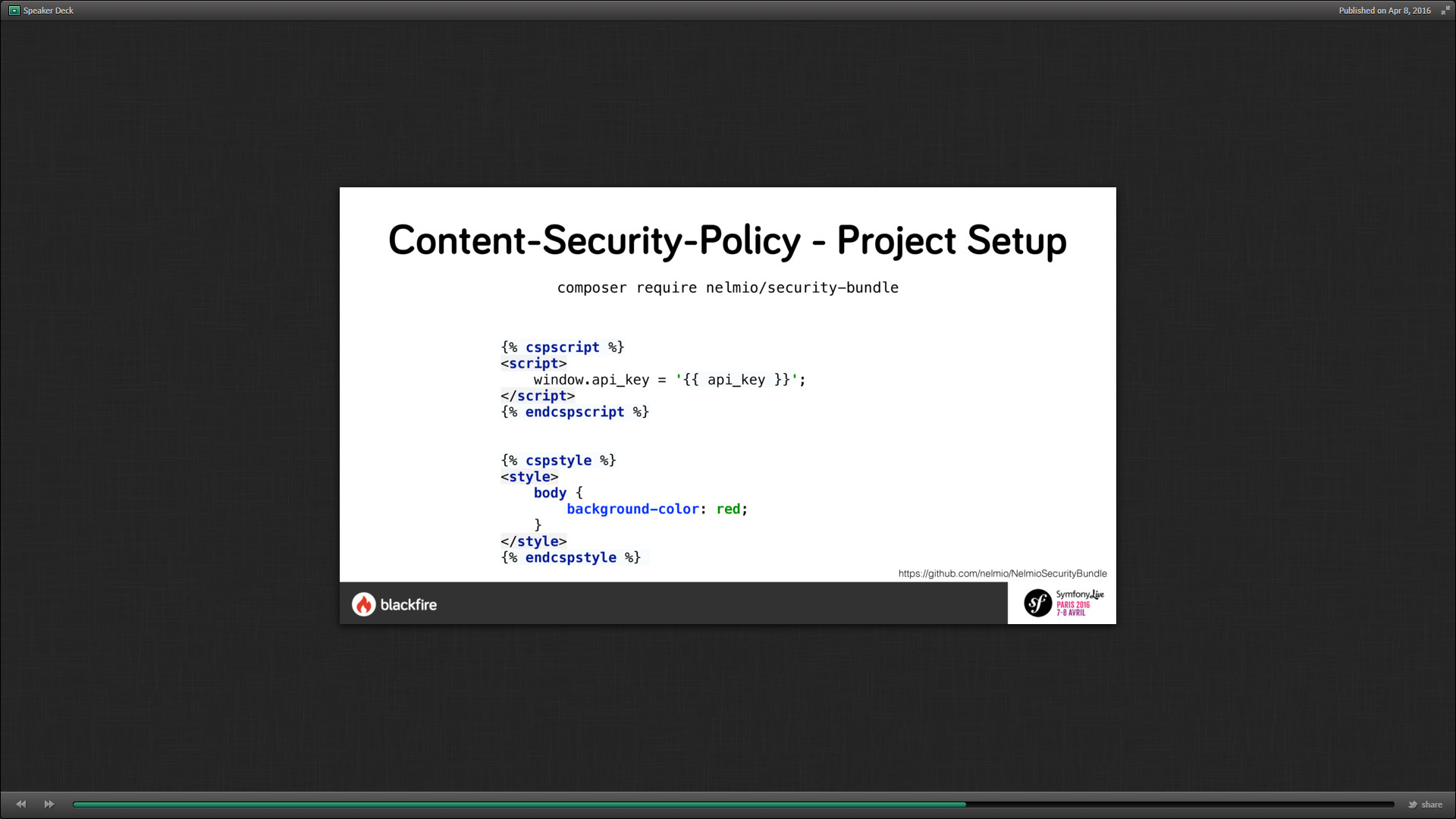
Il est compatible avec AngularJS.
Subresource Integrity
Malgré tout, il reste encore quelques failles telles que les extensions navigateurs, les trackers comme google analytique (à retirer des pages contenant des formulaires) et des CDN. C’est pourquoi Subresource Integrity a été mis en place et est recommandé par W3C depuis 2015. Il permet de vérifier que la source reçu n’a pas été manipulée.
Applications dans le cloud
(par Ori Pekelman)
Avec le cloud, les applications web doivent de plus en plus être indépendantes de l’infrastructure. Lors de sa mise en œuvre, il est difficile de prévoir les charges nécessaires, son succès peut amener à la migrer sur de multiples infrastructures. Ou encore, déployer son application sur des CDN pour la booster ses performances.
C’est pourquoi il est utile de séparer les configurations liées au hardware du code source des applications.
Un exemple de mise en œuvre d’une application cloud.

cdn
Le cdn est utilisé pour toutes les pages frontales en plus des assets (js, css).
Il permet de rendre le site très rapide (haute disponibilité) et d’absorber les pics irréguliers. Il tourne sur de multiples infrastructures et leurs migrations sont faciles à réaliser. Le déploiement continu est également possible.
ESI est une bonne solution en mettant les pages en cache sur ce cdn.
Dans Symfony, il est implémentable dans config.yml dans la partie framework : esi: true et il suffit de renseigner l’annotation @Cache. Nous pouvons ainsi mettre toute une page en cache et laisser quelques informations en dynamique (zone d’identification ou panier).
Dans twig, utiliser {{ render_esi(uri, options) }} pour intégrer les blocs et {{ render_hinclude(controller,{template}) }} pour de l’asynchrone.
entry point
Le lien entre les visuels contenus dans le cdn et l’application est gérer par un système de routage, un load balancer par exemple.
Micro-services et Queue Message
L’applicatif est divisé en micro-services, lesquels remplissent tous une fonction simple et indépendante des autres services. Ainsi son hébergement peut être divisé selon les besoins et les charges.
Cependant la communication entre chaque brique est coûteuse. Une requête http est envoyée pour chaque interaction et affaiblit ainsi les performances.
C’est pourquoi il est conseillé d’opter pour une exécution asynchrone des actions. Seul le premier appel permettant de renvoyer le résultat attendu est synchrone et les traitements sont déclenchés en différé. C’est là que le Message Queue intervient pour gérer les files d’attente des actions et faire le lien entre l’applicatif et les datas. L’action ne coûte donc qu’une requête http et les apis permettent de faire le lien avec le MQ.
Pour utiliser le Message Queue dans Synfony : https://github.com/swarrot/swarrot
Moteur de recherche et database
Le moteur de recherche est idéal pour plus de rapidité : ElasticSearch. Il nous permet dans cette solution de lire les données et récupérer les facets.
Mais la base de données est toujours nécessaire pour les informations transactionnelles : MariaDB. Il sert à leur écriture mais en différé, ce qui n’implique pas les temps d’exécution pour l’utilisateur. Cette architecture permet facilement de faire cohabiter plusieurs bases en maître / esclave réplication synchrone.
Cache
Pour de meilleures performances, il faut déléguer le cache à l’infrastructure qui est plus adaptée pour répondre aux problématiques de gestion de cache. Varnish, reverse proxy…
Déploiement
L’applicatif ne doit pas être lié à l’environnement. Toutes informations de l’infrastructure sont envoyées par le serveur et utiliser anonymement par l’application. Lors du développement, il faut bien détacher cette notion.
La production est en lecture seule, les données seules sont en lecture / écriture.